
User:Joca/Project proposal: Difference between revisions
No edit summary |
|||
| Line 65: | Line 65: | ||
<div style='max-width: 45rem; margin: 0 auto;'> | <div style='max-width: 45rem; margin: 0 auto;'> | ||
=== Tools and form === | === Tools and form === | ||
I'd like to have the interfaces running on individual smart speakers. In earlier stages of the project I experimented with the the Google Assistant platform, and open-source alternatives like MyCroft or Jasper. These posed some problems in terms of flexibility (Google) and quality of the speech recognition and speech synthesis (Mycroft, Jasper). | |||
I | Currently I imagine a setup where the logic runs on a central computer hidden away. Connected to this computer are the speakers on stage. These feature a loudspeaker, a microphone and LED's, which are connected to a microcontroller and a usb audio interface connected to the central computer. | ||
It is a good basis to further develop for the graduation show. I aim to take a more spatial approach there, | For the speech recognition and speech synthesis I prefer an approach that is not fully depending on the cloud services of Google and Amazon. This support archiving the project in the future, and is technically interesting: Do we really need the cloud for these type of projects? After several tests I found a number of tools that are suitable for my project: | ||
MaryTTS - Open source text to speech synthesis, developed by DFKI university. | |||
Porcupine - Hotword detection | |||
Snips ASR - A closed-source fork of the open source Kaldi speech to text toolkit. It is designed to work locally, using low performance computers. It's license is fully open for non-commercial use of the platform, including modifying the software. | |||
Snips or Rasa NLU - Open source toolkits for entity recognition and natural language processing. This software makes the transcribed speech parsable for the software, so my script is able to recognize particular keywords. | |||
It is a good basis to further develop for the graduation show. I aim to take a more spatial approach there, in the form of a small table as a stage for the smart speakers, including a small set-up with spotlights for example. | |||
===Who can help?=== | ===Who can help?=== | ||
Latest revision as of 12:40, 27 March 2019

Project proposal
Joca van der Horst / 21-11-18 (small updates on 25-03-19) / XPUB
Conversational interfaces that provoke a different view on news
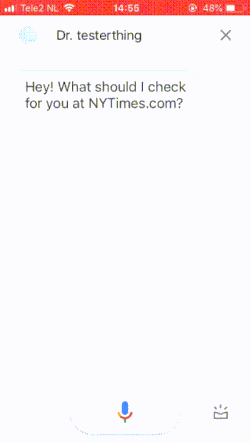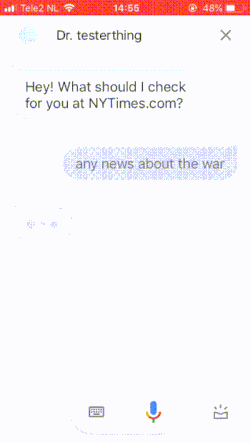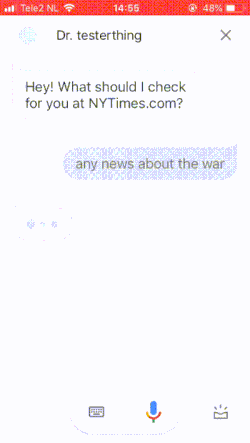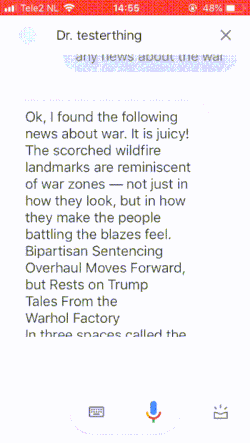
Within this project, I want to research the role of the interface in the field of digital news media on how people interpret information. I am especially interested in how an interface could facilitate critical insight while reading the news, and I think that a conversational interface like a smart speaker can be a good medium for that.
To explore this idea I want to design a number of smart speakers that tell a news story in the form of a theatre play. Each of these interfaces would have its own personality that represents a way of looking at the news. This can be connected to a particular politic view (populist, liberal) or a way of thinking (rationalistic, humanistic). This character is reflected in the way the interfaces talk, but also in the design of the smart speaker they 'live' in.
The content that is used by the speakers will be based on theatre scripts that I write. This scripts feature text, but also audio fragments from other sources like podcasts and Librivox. For the interaction between human and system, I'd like to challenge the idea of the conversational interface as a digital assistant only.
One of the stories I am considering is the problematic aspect of privacy and smart speakers. For this story I imagine an interrogation of a Google Home speaker, by a number of my speakers. The setting would be modelled after the congress hearings different Silicon Valley CEO's. My 'rogue' speakers interview the Google Speaker and let the audience decide in the end: Can the Google smart speaker continue, or should we pull the plug?
Another set-up that I am considering is the use of standard use-cases of smart speakers to intervene. The starting point is then that someone asks for the weater, news, or setting a timer. Instead of the expected behaviour, an act of the theatre play starts. In case of the weather information scenario, imagine that there are two speakers. One could give the information on the person's request. Then the other speakers intervenes by saying that it is warmer than usual, asking the human for its feelings about that.
Why journalism?
Journalism is an interesting field to design for, as many societal phenomena meet in this field. Currently, the most used news media are digital. This opens up possibilities for new ways of storytelling, and involving readers as experts for example. But it also poses challenges: How to guarantee the independence of news media while finding ways to survive using advertisements and subscriptions. Trust in journalism is not self-evident anymore.
In that sense journalism is wicked, both exciting and possibly open to evil.
Conversational interfaces are an interesting medium to research, as many aspects come together here: dependence on external platforms like the clouds of Google and Amazon. The promise of new ways to engage users, and the failure of current interfaces which leaves people confused about the origin of the news they are getting. (Brandom, 2018)
Currently, the dominant principles for an interface are drafted from design practices that originate from the field of Human-Computer Interaction. These are based on solving problems efficiently, creating a user-centered design to fulfill a task and reach a goal as quick and easy as possible. Within this ideology, the conversational interface should be a digital assistant. This might be effective for setting a timer in the kitchen, but is this the best way to interface journalism?
 source: https://www.blog.google/products/news/hey-google-whats-news/
source: https://www.blog.google/products/news/hey-google-whats-news/
Related discourse in the field

The role of journalism is discussed from different perspectives nowadays. Research institutions like the Nieman Journalism Lab try to experiment with existing media. New publications are founded by start-ups like The Correspondent and Buzzfeed. The latter started Buzzfeed News because it sees potential in offering serious journalism next to the juicy listicles it got known for. (Saba, 2014)
At the same time, technology companies like Apple, Facebook, and Google try to aggregate different news sources, because news is interesting content for their platforms as a way to attract an engaged audience.

Smart assistants that live in speakers are the newest way to expand their platform. After years of speculation about computers to which we can talk, e.g. expert systems (Flores en Winograd, 1980), conversational interfaces are now really entering the mainstream. Already one-third of the US households have a smart speaker. (Molla, 2018) In the meantime, audio is getting more traction at news media too. The New York times invest heavily in podcasts for example. (Salmon, 2018)
Though, no matter what platform, and (digital) medium, there is an interface around the content. The way these are structured comes nowadays mostly from User Experience Design (UX). In the nineties, the term UX was coined as a way to collect all aspects of user interaction with the products and services of a company. (Nielsen & Norman, 1998) The popular school of UX as started by Nielsen en Norman adds some psychology to it and focuses on 'transparent' interfaces that design an 'affordance of experiences'. In the end, it results in interfaces with unambiguous clues that work for a particular narrow scenario to get a job done easily. (Lialina, 2018) Conversational interfaces are quite new, and currently these same principles.
There are however alternative approaches to this rationalistic way of interaction design. In Graphesis (2014), Johanna Drucker describes a visual interface design that is focused on displaying ambiguity and offers ways to structure critical insights. She coins the term Humanistic Interface for this. Olia Lialina (2018) refers to the concept of forgiveness in interfaces.
Although most of these models focus on Graphical User Interfaces, I think they can give a clue for the creation of a conversational interface that is something different than the commonly used assistant archetype. Given the adoption rate of smart speakers, and the opportunities for news publications in this field, it is relevant to investigate this particular use of a conversational interface.

Relation to previous practice
Before I started at Experimental Publishing, I already had some experience in writing and journalism. During my bachelors, I learned about interaction design, for both tangible and digital interfaces. Pairing these experiences with what I learned about critical theory and digital culture at the Piet Zwart, I see a good starting point to dive into this topic and connect these different perspectives.
Looking at the projects of last year, both the Non-human Librarians of the XPPL and Reading the Structure intervene with text, in such a way that it opens up questions about the interface, and its influence on how users perceive the content via it; be it a text, or an entire collection of books.
The interfaces I designed during my Bachelor's focus more on tangible and embodied interaction, a style of human-computer interaction that focused discovery and participation and links well to the ideas behind Drucker's model of performative materiality (2013).
Making the project
Tools and form
I'd like to have the interfaces running on individual smart speakers. In earlier stages of the project I experimented with the the Google Assistant platform, and open-source alternatives like MyCroft or Jasper. These posed some problems in terms of flexibility (Google) and quality of the speech recognition and speech synthesis (Mycroft, Jasper).
Currently I imagine a setup where the logic runs on a central computer hidden away. Connected to this computer are the speakers on stage. These feature a loudspeaker, a microphone and LED's, which are connected to a microcontroller and a usb audio interface connected to the central computer.
For the speech recognition and speech synthesis I prefer an approach that is not fully depending on the cloud services of Google and Amazon. This support archiving the project in the future, and is technically interesting: Do we really need the cloud for these type of projects? After several tests I found a number of tools that are suitable for my project:
MaryTTS - Open source text to speech synthesis, developed by DFKI university. Porcupine - Hotword detection Snips ASR - A closed-source fork of the open source Kaldi speech to text toolkit. It is designed to work locally, using low performance computers. It's license is fully open for non-commercial use of the platform, including modifying the software. Snips or Rasa NLU - Open source toolkits for entity recognition and natural language processing. This software makes the transcribed speech parsable for the software, so my script is able to recognize particular keywords.
It is a good basis to further develop for the graduation show. I aim to take a more spatial approach there, in the form of a small table as a stage for the smart speakers, including a small set-up with spotlights for example.
Who can help?
At XPUB Clara Balaguer and Amy Wu can help me on a conceptual level and with the visual aspect of the project. Steve Rushton can give new insights for my thesis. Michael Murtaugh and André Castro are great resources for the technical realization of the project, especially building the backend of the system for scraping and cataloging content from news media. Discussions with Aymeric Maysoux and my classmates will help to zoom out, and critically look at the project as a whole, before zooming back in on specific aspects.
Outside of the Piet Zwart, it is good to connect to the various initiatives in the Netherlands that try to pair journalists with designers and developers, like ACED and the Stimuleringsfonds voor de Journalistiek. I am also planning on reaching out to Olia Lialina, because of her research on affordances in Human-Robot Interaction. Next to that, it is useful to contact other designers I know who did design projects in the field of journalism and interfaces, like Martina Hyunh, Maxime Benvenuto and Jim Brady.

{kind=link}
{kind=link}
{kind=link}
Timetable
Oktober/ First half of November
Thesis outline and project proposal. Setting up a theoretical framework, building an annotated bibliography. Scoping the project (using insights from prototyping)
Second half of November/December
Writing the first chapter, further prototyping, choosing the medium for the interface
January
Further writing. Evaluating prototypes made so far. Further developing specific directions
February/March
Further writing, first complete draft thesis. Realization of the project. Detailing form and production process of the thesis.
May/June
Finetuning thesis and project. Producing the items needed to present the project to a wide audience during the graduation show (and beyond. Online, possibly other events etc. )
July
Rest and reflect on the things I learned. Check possibilities to show the project at other events in the form of an exhibition, workshop etc.
References
Brandom, R. (2018, November 18). Smart speakers have no idea how to give us news. Retrieved from https://www.theverge.com/2018/11/18/18099203/smart-speakers-news-amazon-echo-google-home-homepod
Drucker, J. (2013) DHQ: Digital Humanities Quarterly: Performative Materiality and Theoretical Approaches to Interface. Digital Humanities Quarterly.
Drucker, J. (2014). Graphesis: Visual forms of knowledge production. Cambridge, MA: Harvard University Press.
Lialina, O. (2018). Once Again, The Doorknob. On Affordance, Forgiveness and Ambiguity in Human Computer and Human Robot Interaction [Conference Talk]. Retrieved from http://contemporary-home-computing.org/affordance/
Molla, R. (2018). Voice tech like Alexa and Siri hasn’t found its true calling yet: Inside the voice assistant ‘revolution.’ Recode Retrieved from https://www.recode.net/2018/11/12/17765390/voice-alexa-siri-assistant-amazon-echo-google-assistant
Newman, N. (2018). The Future of Voice and the Implications for News. Reuters Institute for the Study of Journalism.
Nielsen, J., & Norman, D. (1998). The Definition of User Experience (UX). Retrieved from https://www.nngroup.com/articles/definition-user-experience/
Saba, J. (2014). Beyond cute cats: How BuzzFeed is reinventing itself. Reuters Retrieved from https://www.reuters.com/article/us-usa-media-buzzfeed/beyond-cute-cats-how-buzzfeed-is-reinventing-itself-idUSBREA1M0IQ20140223
Salmon, F. (2018, March 7). The Improbable Rise of the Daily News Podcast. Wired. Retrieved from https://www.wired.com/story/rise-of-daily-news-podcasts/
Winograd, T., & Flores, F. (2008). Understanding computers and cognition : a new foundation for design (24th ed.). Boston: Addison-Wesley.