
Andreas Image Appropriation I: Difference between revisions
No edit summary |
No edit summary |
||
| (8 intermediate revisions by the same user not shown) | |||
| Line 1: | Line 1: | ||
In the ''Image Appropriation (I)'' with Javi we played around with the ''Download All Images'' Extension for Firefox Quantum: https://add0n.com/save-images.html <br> | |||
=The Research= | |||
Using this extension I tried to do a snapshot of various | Using this extension I tried to do a snapshot of various news sites online. | ||
What kind of photos are on display? | <br> | ||
<br> | |||
Which site is triggering emotions? | What does the imagery – regardless of the webdesign/visual appearance – of each news site look like?<br> | ||
Is the site heavily influenced by | What kind of photos are on display? (for example portraits, landscapes)<br> | ||
Which site is triggering emotions? (for example overexaggerated facial expressions)<br> | |||
Is the site heavily influenced by advertisement imagery? | |||
=The Results= | =The Results: News sites on 10-1-2018 between 3:50 and 3:57 PM= | ||
Here you can find all the scraped images with the timestamp in alphabetical order: | Here you can find all the scraped images with the timestamp in alphabetical order: | ||
| Line 21: | Line 23: | ||
File:NBC_News_-_Breaking_News_-_Top_Stories_-_Latest_World-_US_-_Local_News_-_NBC_News_-_10-1-2018_3-54-15_PM_001.jpg|www.nbcnews.com | File:NBC_News_-_Breaking_News_-_Top_Stories_-_Latest_World-_US_-_Local_News_-_NBC_News_-_10-1-2018_3-54-15_PM_001.jpg|www.nbcnews.com | ||
File:The_New_York_Times_-_Breaking_News-_World_News_-_Multimedia_-_10-1-2018_3-51-42_PM.jpg|www.nytimes.com | File:The_New_York_Times_-_Breaking_News-_World_News_-_Multimedia_-_10-1-2018_3-51-42_PM.jpg|www.nytimes.com | ||
File: | File:SPIEGEL_ONLINE_-_Aktuelle_Nachrichten_-_10-1-2018_3-54-43_PM_001.jpg|www.spiegel.de | ||
File: | File:Nachrichten-_Hintergründe_-_Reportagen_-_STERN-de_-_10-1-2018_3-55-01_PM_001.jpg|www.stern.de | ||
File:News-_sport_and_opinion_from_the_Guardian-s_global_edition_-_The_Guardian_-_10-1-2018_3-54-26_PM_001.jpg|www.theguardian.com | |||
File:News-_sport-_celebrities_and_gossip_-_The_Sun_-_10-1-2018_3-57-47_PM_001.jpg|www.thesun.co.uk | |||
File:ZEIT_ONLINE_-_Nachrichten-_Hintergründe_und_Debatten_-_10-1-2018_3-50-12_PM.jpg|www.zeit.de | |||
</gallery> | </gallery> | ||
| Line 28: | Line 33: | ||
<br> | <br> | ||
=Outlook= | =Outlook= | ||
Of course there can be done various improvements. Because I was manually triggering the extension there is a small time | Of course there can be done various improvements. Because I was manually triggering the extension there is a small time difference inbetween scraping the various sites. To have a neutral overview, the script would have to download the imagery for all pages simultaneous at exactly the same time.<br> | ||
In addition, the extension seems to have trouble to download all pictures on some webpages. I still have to do some test runs with various parameters (Deep Search Levels and so on…) | |||
[[User:Andreas|<u>Go back to Andreas' page</u>]] | [[User:Andreas|<u>Go back to Andreas' page</u>]] | ||
Latest revision as of 22:40, 1 October 2018
In the Image Appropriation (I) with Javi we played around with the Download All Images Extension for Firefox Quantum: https://add0n.com/save-images.html
The Research
Using this extension I tried to do a snapshot of various news sites online.
What does the imagery – regardless of the webdesign/visual appearance – of each news site look like?
What kind of photos are on display? (for example portraits, landscapes)
Which site is triggering emotions? (for example overexaggerated facial expressions)
Is the site heavily influenced by advertisement imagery?
The Results: News sites on 10-1-2018 between 3:50 and 3:57 PM
Here you can find all the scraped images with the timestamp in alphabetical order:
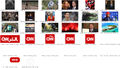
edition.cnn.com

eu.usatoday.com

www.bbc.com

www.foxnews.com
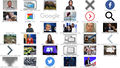
www.independent.co.uk
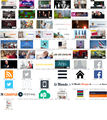
www.lemonde.fr

www.nbcnews.com
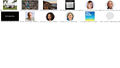
www.nytimes.com
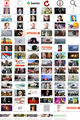
www.spiegel.de

www.stern.de
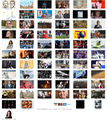
www.theguardian.com

www.thesun.co.uk
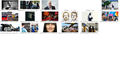
www.zeit.de












Outlook
Of course there can be done various improvements. Because I was manually triggering the extension there is a small time difference inbetween scraping the various sites. To have a neutral overview, the script would have to download the imagery for all pages simultaneous at exactly the same time.
In addition, the extension seems to have trouble to download all pictures on some webpages. I still have to do some test runs with various parameters (Deep Search Levels and so on…)