
User:Tash/Prototyping 02
Python Research: NLTK Synonyms
Using NLTK to create python script which will:
- read text input (using stdin)
- use NLTK Wordnet package to search for synonyms of each word
- use for loop and append function to replace each word with a synonym
- print text output (using stdout)
Original tutorial: Using WordNet to get synonymous words
from https://likegeeks.com/nlp-tutorial-using-python-nltk/
from nltk.corpus import wordnet
synonyms = []
for syn in wordnet.synsets('Computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)
The output is:
['computer', 'computing_machine', 'computing_device', 'data_processor', 'electronic_computer', 'information_processing_system', 'calculator', 'reckoner', 'figurer', 'estimator', 'computer']
I edited the script to use stdin, stderr, stdout, loops and also added if functions to debug some flaws:
from nltk.corpus import wordnet
from sys import stdin, stderr, stdout
import random
print ("Type in some text. Don't forget to CTRL D to end file.", file=stderr)
sentence=stdin.read()
#Empty list which will be used for output:
newsentence = []
#Empty list which is used to collect unusable synonyms:
trash = []
words=sentence.split()
for x in words:
print ("Processing:", x, file=stderr)
print ("", file=stderr)
#The NLTK package has a bug - it recognizes the article 'a' as a noun and gives unusable synonyms for it.
#This if function stops the script from processing any instances of 'a'.
if (x == 'a' or x =='A'):
newsentence.append(x)
else:
synonyms = []
for syn in wordnet.synsets(x):
for lemma in syn.lemmas():
i = lemma.name().strip()
if i == x:
trash.append(i)
else:
synonyms.append(i)
#This if function counts the number of synonyms that WordNet returns.
#If there are no synonyms found it will append the original word.
if len(synonyms) == 0:
newsentence.append(x)
else:
#This else option returns the next synonym as found by WordNet.
# nextsyn = synonyms[0]
# print ("Next synonym:", nextsyn, file=stderr)
# print ("", file=stderr)
# newsentence.append(nextsyn)
#This else option returns a random synonym.
print (synonyms, file=stderr)
r = (random.choice(synonyms))
print ("Randomizer:", r, file=stderr)
print ("", file=stderr)
newsentence.append(r)
print ("New sentence:", " ".join(newsentence))
Python Research: William Burroughs script
This script is inspired by William Burroughs idea that words like 'the', 'either' and 'or' are viruses which need to be eliminated from language.
From The Electronic Revolution (1970)
"The categorical THE is a virus mechanism, locking you in THE virus universe... THE now, THE past, THE time, THE space, THE energy, THE matter. Definite article THE contains the implications of no other. IIf other universes are possible, then the universe is no longer THE it becomes A. The definite article THE is deleted and replaced by A. EITHER/OR is another virus formula. It is always you OR the virus. EITHER/OR. This is in point of fact the conflict formula which is seen to be archetypical virus mechanism. The proposed language will delete these virus mechanisms and make them impossible of formulation in the language."
from sys import stdin, stderr, stdout
print ("Type in some text. Don't forget to CTRL D to end file.", file=stderr)
sentence=stdin.read()
#Empty lists which will be used for output:
newsentence = []
newsentence2 = []
words=sentence.split()
for x in words:
print ("Processing:", x, file=stderr)
print ("", file=stderr)
#Find instances of 't/The' and 'E/either' and 'O/or'
if (x == 'The' or x =='the'):
newsentence.append('a')
else:
newsentence.append(x)
for i in newsentence:
if (i == 'Or' or i =='or' or i == 'Either' or i == 'either'):
newsentence2.append('also')
else:
newsentence2.append(i)
print ("New sentence:", " ".join(newsentence2))
Example input:
the truth you are either good or evil.
Example output:
a truth is you are also good also evil.
OCR with Tesseract
To OCR a scanned file in english and create a text file output:
tesseract <inputfilename> <outputfilename>
To OCR a PNG file in english and create a text file output, and then convert it to hocr:
tesseract <inputfilename> <outputfilename> hocr
Independent Research: Retraining Tesseract
Tesseract can be trained to detect new fonts. You can also retrain or alter existing training data, on a character / font level or even on a word / dictionary level. To train tesseract, download the correct version of Tesseract (3 or higher). Make sure to install it with training tools:
brew install --with-training-tools tesseract
OPTION 1: MAKE NEW TRAINING DATA
1. Download a box editor program to make a box file & image file that tell Tesseract how to recognize symbols and characters.
E.g. Moshpytt.py. Problem with Moshpytt on Mac: there are a few dependencies you have to download, like pyGTK.
I did this both through brew and pip, but somehow running moshpytt.py still returned the error: No module found.
The internet suggests this is because I'm using my Mac’s system python, which can’t find the brew pygtk file.
I'd have to somehow fix this using a PATH command - but haven't managed to figure this out yet
2. Use the box editor to set how you want Tesseract to (mis)interpret characters. Save the file and then open the automatic training script 'autotrain.py':
Before you run the script, make sure to specify where the tessdata directory is on your system:
def __init__(self):
self.tessdataDirectory = '/usr/local/share/tessdata'
Save the python file, then open terminal and make sure you are in the directory holding your image/boxfile pair.
From here, run autotrain.py, which will execute the following:
- Work out the language and a list of fonts present
- Generate .tr files from each boxfile
- Concatenate all .tr and .box files for each font into single files
- Run unicharset_extractor on the boxfiles
- Run mftraining and cntraining
- Rename the output files to include the language prefix
- Run combine_tessdata on all the generated files
- Move the lang.traineddata file to the tesseract / tessdata directory.
OPTION 2: ALTER EXISTING TRAINING DATA
Knowing the above, you can also go in via the backdoor. Instead of making new files, extract the existing training data, and change the .tr and .box files of each font.
1. Find the 'tessdata' directory, that’s where the training files are:
cd / && sudo find . -iname tessdata
cd ./usr/local/Cellar/tesseract/3.05.01/share/tessdata
2. In /tessdata you'll find combined packages of training files in the languages you have download. E.g. eng.traineddata. To extract and unpack the components:
combine_tessdata -u eng.traineddata <prefix>
This will create the separate files in the same directory, including a unicharset file containing boxfiles, and a series of 'DAWG' files: Directed Acrylic Word Graphs. These are dictionary files used by Tesseract during the OCR process to help it determine if the string of characters it has identified as a word is correct. This might be interesting to hack, because if the confidence that Tesseract has in the characters in a word is sufficiently low so that changing these characters will cause the “word” to be changed into something that exists in the dictionary, Tesseract will make the correction. You can turn any word list into a DAWG file using Tesseract’s wordlist2dawg utility. The word list files must be .txt files with one word per line.
To turn DAWG files back into .txt files
dawg2wordlist eng.unicharset eng.word-dawg wordlistfile.txt
There are several different types of DAWG files and each is optional so you can replace only the ones you want. These two are most common:
<lang>.word-dawg: A dawg made from dictionary words from the language.
<lang>.freq-dawg: A dawg made from the most frequent words which would have gone into word-dawg.
3. Run unicharset_extractor on the boxfiles, which should be called /eng.unicharset Edit them to recognize / misrecognize letters as you like, and resave them using box editor
4. Once you have your new boxfiles, either use the moshpytt autotrain.py script or use combine_tessdata utility to manually pack them back into a new set of <lang>.traineddata file.
To use new training data:
tesseract <inputfilename> <outputfilename> -l <lang>
Independent Research: Sonification


1. Experiments with digital sound -> digital image
To use sox to create raw audio files, first we make sure the file is in an uncompressed format
So: use ffmpeg to turn mp3 to a signed 16 bit wav file
ffmpeg -i audio.mp3 -acodec pcm_s16le -ar 44100 FaxMachine.wav
audio -> image use imagemagick to convert raw audio file to gif or other image file
image -> audio use imagemagick to convert image file back to raw file, use sox to play raw file
play -b 16 --endian little -e signed -r 44100 -c 1 FaxMachine.gif.raw
to save as wav file
sox -r 44100 -e unsigned -b 8 -c 1 <RAW_FILE> <TARGET_FILE>
2. Independent research on spectrograms
A spectrogram is:
A visual representation of the spectrum of frequencies of sound or other signal as they vary with time. Spectrograms are sometimes called spectral waterfalls, voiceprints, or voicegrams.
Spectrograms can be used to identify spoken words phonetically, and to analyse the various calls of animals. They are used extensively in the development of the fields of music, sonar, radar, and speech processing, seismology, and others. (https://en.wikipedia.org/wiki/Spectrogram)
See: https://musiclab.chromeexperiments.com/Spectrogram
I found out sox can produce spectrograms from wav files:
sox <inputfile.wav> -n spectrogram -o <outputfile.png>

Output of simple tones: FaxMachine.wav
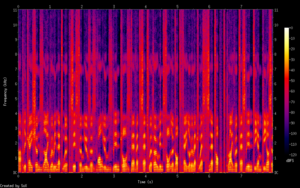
Output of espeak reading out text: filesystem.wav
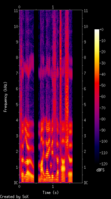
Output of espeak reading out "Hello, my name is Natasha"



Arss is a program which can analyse wav files, produce spectrograms and then decode them back into sound: http://arss.sourceforge.net/examples.shtml
Going forward
- New things this trimester: python, nltk, machine learning concepts, algorithmic literature, using git, building the book scanner, pure / raw data
- Explored what I wanted from last trimester: language, value systems in software, designing the rules and not the output > LOVED this. I really enjoy not having full control of the outcome.
- To get into in the future:
- performative and material aspects of software
- more on machine learning / data mining / algorithmic bias / the idea that tech is ever value neutral (again, questioning seamlessness and transparency)
- ref: http://aiweirdness.com
- ref: http://www.mondotheque.be/wiki/index.php/A_bag_but_is_language_nothing_of_words
"Whether speaking of bales of cotton, barrels of oil, or bags of words, what links these subjects [mining processes] is the way in which the notion of "raw material" obscures the labor and power structures employed to secure them. "Raw" is always relative: "purity" depends on processes of "refinement" that typically carry social/ecological impact. Stripping language of order is an act of "disembodiment", detaching it from the acts of writing and reading. The shift from (human) reading to machine reading involves a shift of responsibility from the individual human body to the obscured responsibilities and seemingly inevitable forces of the "machine", be it the machine of a market or the machine of an algorithm."