User:Francg/expub/thesis/prototype
Prototype
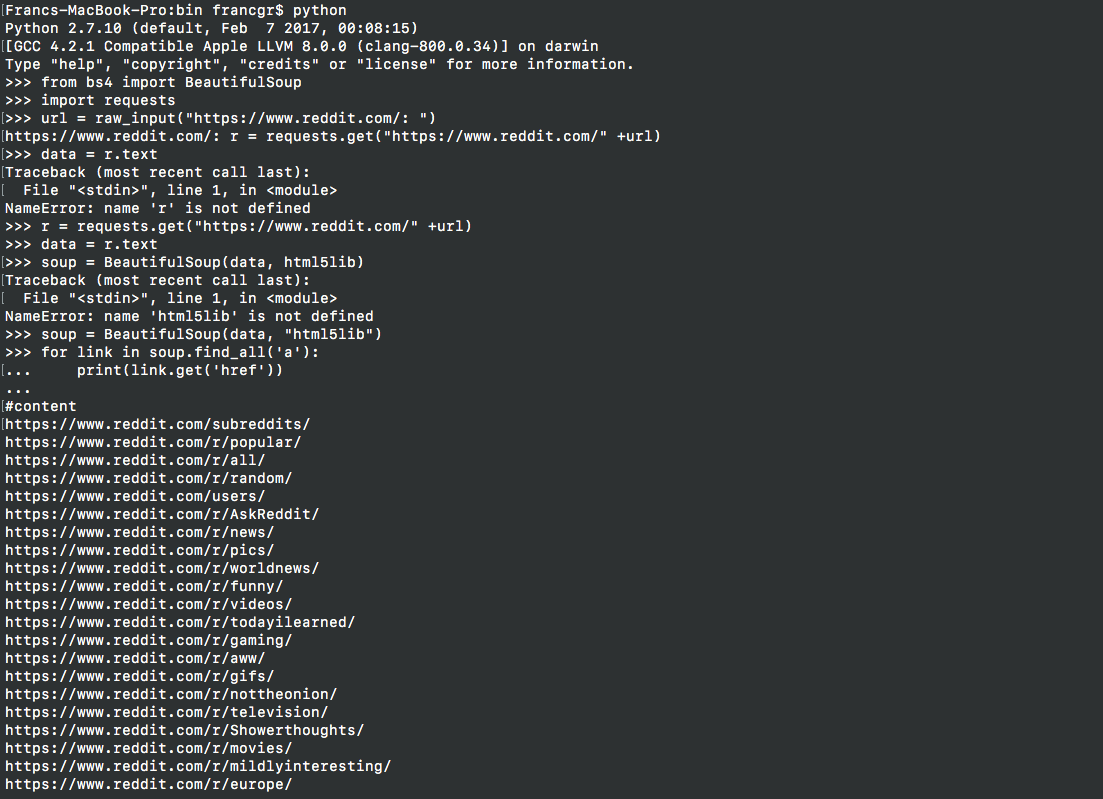
Extracting data (scrapping URL's / web links from content only)
from: https://www.reddit.com/
Run Python (I did it from virtual environment)
from bs4 import BeautifulSoup
import requests
url = raw_input("https://www.reddit.com/: ")
r = requests.get("https://www.reddit.com/" +url)
data = r.text
soup = BeautifulSoup(data)
for link in soup.find_all('a'):
print(link.get('href'))