User:Francg/expub/thesis/hackpackt
Diffengine prototypes
- Installing Diffengine
- Selecting RSS news feed (online journalism)
- Configuring diffengine to check out feeds every 5 min
- Monitor RSS feeds and download content changes (if there are) as jpg & html
Forthcoming prototypes:
- Install Twarc to extract content updated content from social media specific users or groups
- Try installing atom/rss feed finder?
- Convert autom html files to txt files using python, as they happen to be created by diffengine
- Use Python + Beautiful Soup to count specific words from txt file and extract a list of most used.
- Compare ranking words on each txt file (rss feed article)
- Upload files (jpg, html or txt) to a database autom as they happen to be created by diffengine
- Install raspberry pi
- Create a database (maybe also a wiki page?)
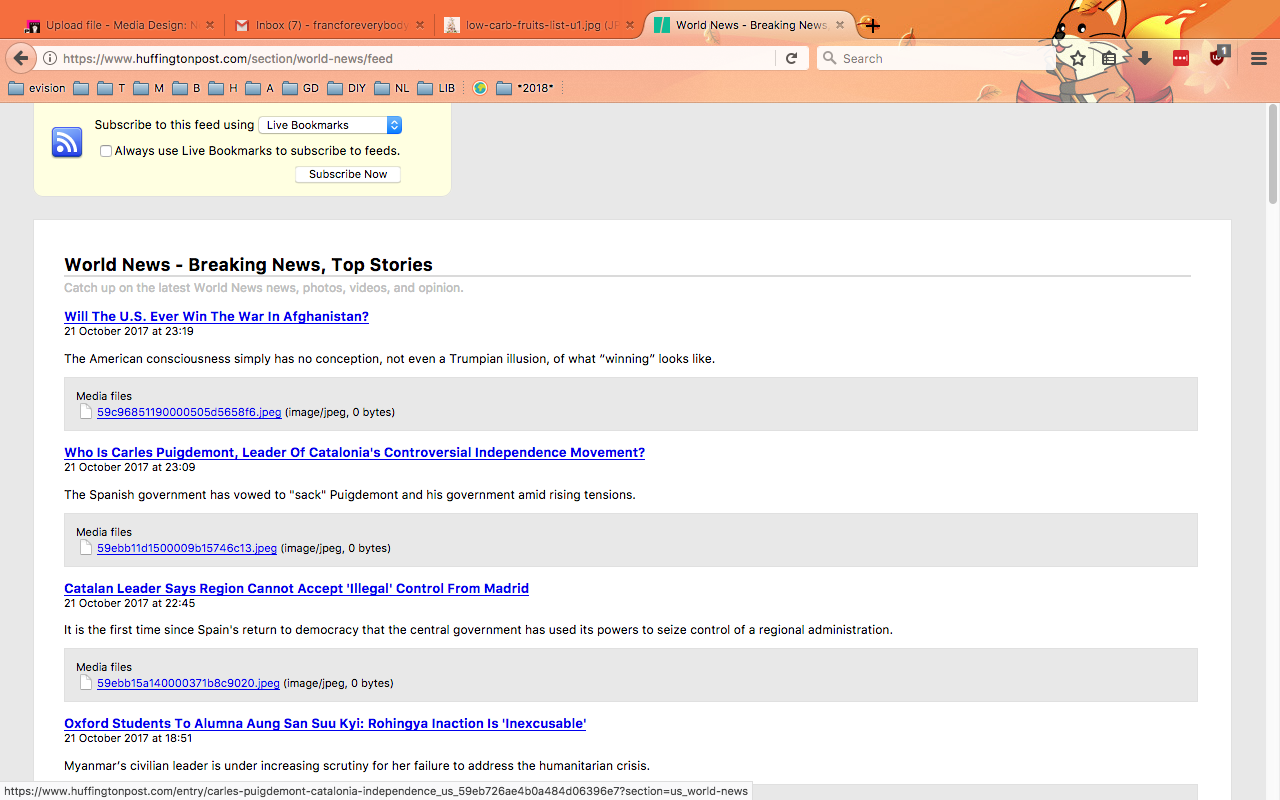
RSS Feed Hunginfton post

What RSS/Atom feed you would you like to monitor?
Would you like to set up tweeting edits? [Y/n]

rundiff.sh > config.yaml > folders > files
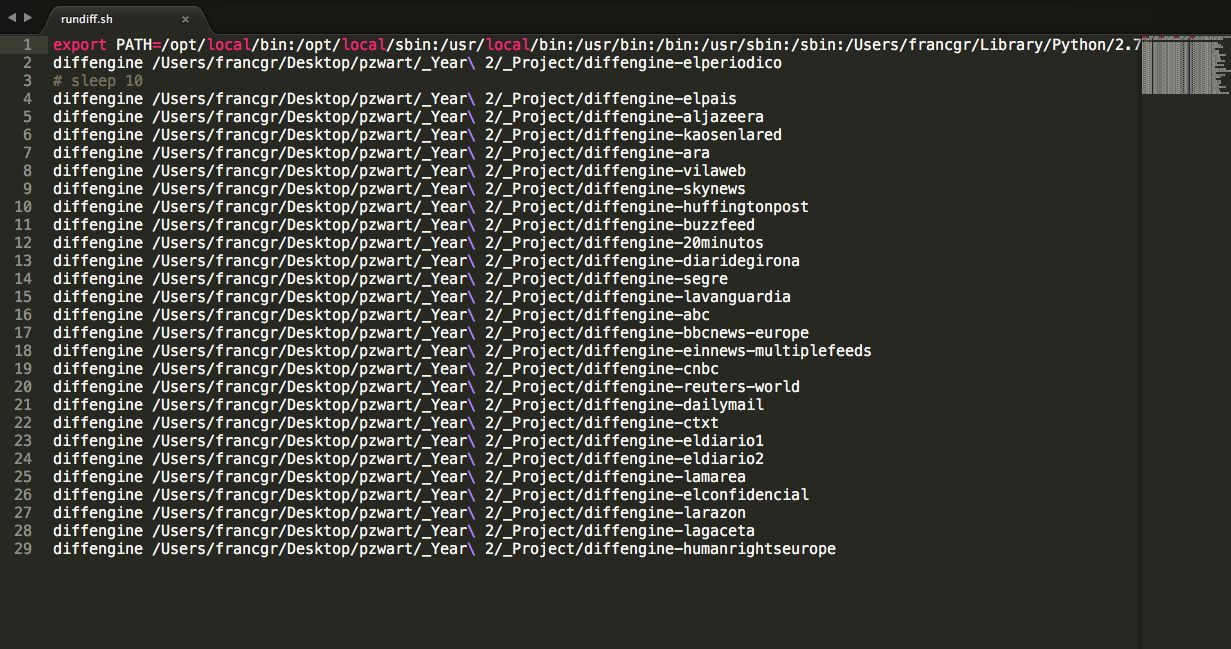
newsfeeds stored and tracking
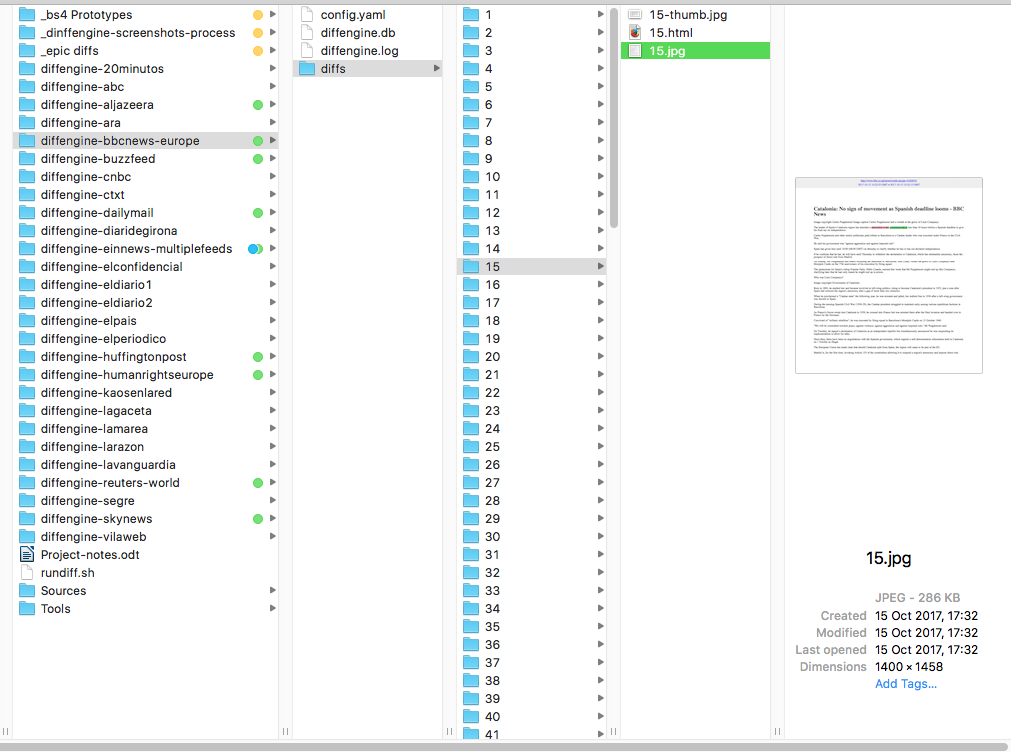
rss newsfeed folders where jpg & html files are created
"You have mail" in Terminal
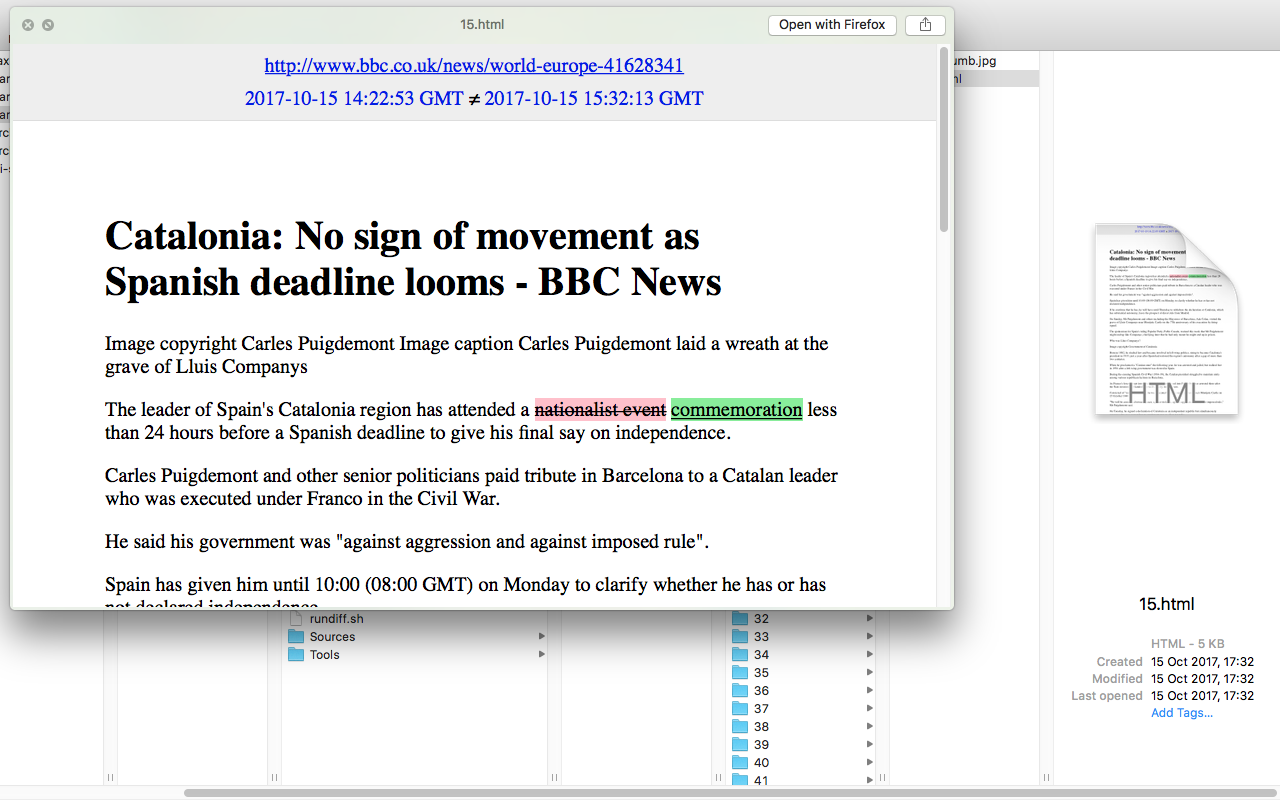
bbcnews
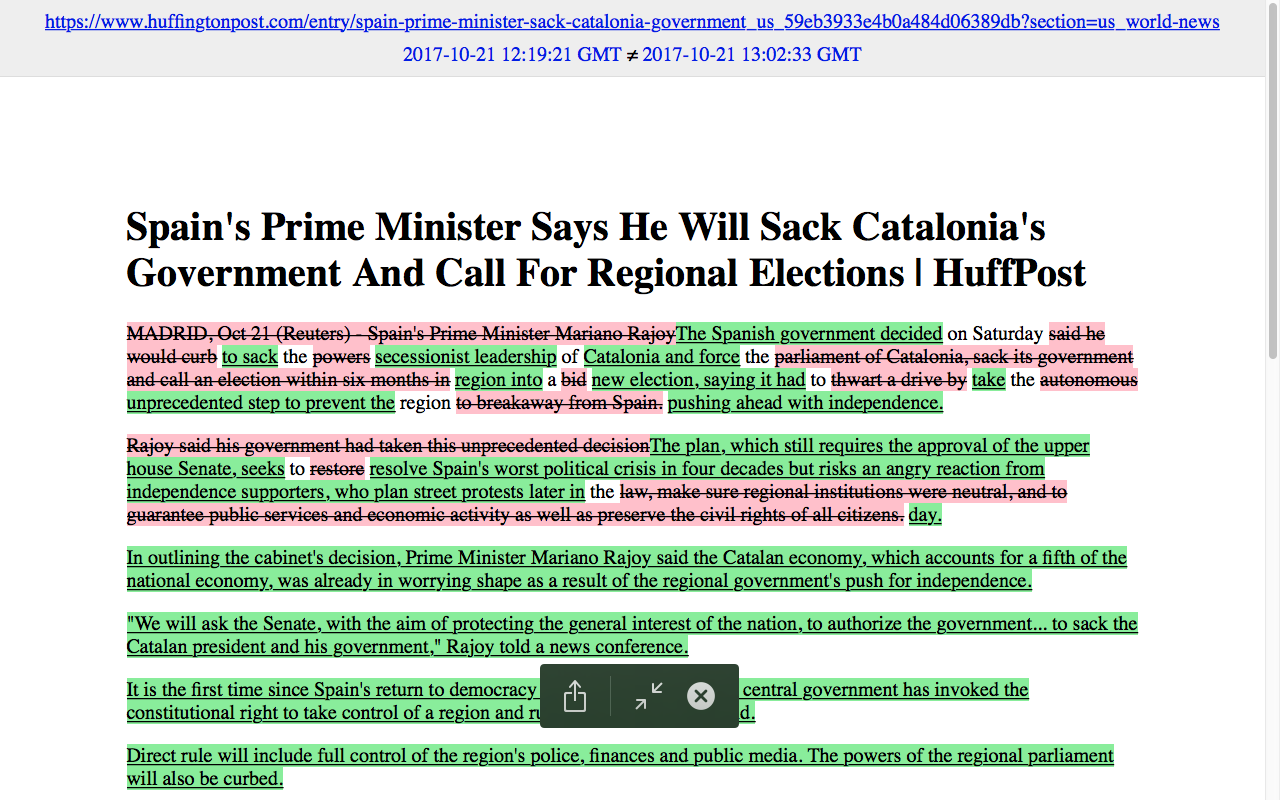
huffingtonpost

















Beautiful Soup prototypes: Extracting structured content and output to txt file