
User:Angeliki/Grad-prototyping: Difference between revisions
| Line 302: | Line 302: | ||
</syntaxhighlight> | </syntaxhighlight> | ||
<img src="https://pzwiki.wdka.nl/mw-mediadesign/images/0/0b/Streaming_FM2text-django.gif" width=100%> | |||
<span style="color:red;">NEXT: scanning through several frequencies and speech recognition </span> | <span style="color:red;">NEXT: scanning through several frequencies and speech recognition </span> | ||
Revision as of 11:14, 30 October 2018
GUIDES
Antennas making: https://sat.weblog.mur.at/
Radio to speech: https://towardsdatascience.com/make-amateur-radio-cool-again-said-mr-artificial-intelligence-36cb32978fb2
Speech tools: http://www.speech.cs.cmu.edu/, https://realpython.com/python-speech-recognition/, https://cmusphinx.github.io/, https://github.com/Uberi/speech_recognition, https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/, http://www.lingoes.net/en/translator/langcode.htm

Zine-machines
coordinates to lines
export GPS data, publish routes/video frames to raw data-publish


import pykml
from pykml import parser
import csv
import re
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
def translate(value, leftMin, leftMax, rightMin, rightMax):
# Figure out how 'wide' each range is
leftSpan = leftMax - leftMin
rightSpan = rightMax - rightMin
# Convert the left range into a 0-1 range (float)
valueScaled = float(value - leftMin) / float(leftSpan)
# Convert the 0-1 range into a value in the right range.
return rightMin + (valueScaled * rightSpan)
kml_file='prlll.kml'
all_routes = {}
with open(kml_file) as f:
doc = parser.parse(f).getroot().Document.Folder
for pm in doc.iterchildren():
if hasattr(pm, 'LineString'):
name = pm.name.text
coordinates = pm.LineString.coordinates.text
cordinatesinline = coordinates.split('\n')
cordinatesasarray = []
for line in cordinatesinline:
pattern = re.compile("^\s+|\s*,\s*|\s+$")
array = [x for x in pattern.split(line) if x]
if array:
cordinatesasarray.append(array)
all_routes[name]= cordinatesasarray
canvas=canvas.Canvas("route.pdf", pagesize=letter)
canvas.setLineWidth(.8)
canvas.setFont('Helvetica', 6)
for name in all_routes:
x=[]
y=[]
for points in all_routes[name]:
x.append(points[0])
y.append(points[1])
i=0
for a in x:
if i < len(x)-1:
x_new=translate(float(x[i]),float(min(x)), float(max(x)),50,500)
y_new=translate(float(y[i]),float(min(y)),float(max(y)),50,500)
x_new2=translate(float(x[i+1]),float(min(x)), float(max(x)),50,500)
y_new2=translate(float(y[i+1]),float(min(y)),float(max(y)),50,500)
print x_new,y_new,x_new2,y_new2
canvas.line(x_new,y_new,x_new2,y_new2)
i=i+1
canvas.drawString(10,45,name)
canvas.showPage()
canvas.save()
Mastodon-bot
A way to publish some text or images to Mastodon (a decentralized, open source social network) using a bot account.
Walking/annotating/listening/transcribing/present voice
Walking the text


Los Banos(PH) voices/ Nomidu Nuna Exhibition

The secrets of pocketsphinx
Acoustic model/training
0 46797 She had your dark suit in greasy wash water all year.
File:
1 Η ο At AtDf Fe|Sg|Nm 2 Atr _ _
2 Σίφνος Σίφνος No NoPr Fe|Sg|Nm 3 Sb _ _
3 φημίζεται φημίζομαι Vb VbMn Id|Pr|03|Sg|Xx|Ip|Pv|Xx 0 Pred _ _
4 και και Cj CjCo _ 5 AuxY _ _
5 για για AsPp AsPpSp _ 3 AuxP _ _
6 τα ο At AtDf Ne|Pl|Ac 8 Atr _ _
7 καταγάλανα καταγάλανος Aj Aj Ba|Ne|Pl|Ac 8 Atr _ _
8 νερά νερό No NoCm Ne|Pl|Ac 5 Obj _ _
9 των ο At AtDf Fe|Pl|Ge 11 Atr _ _
10 πανέμορφων πανέμορφος Aj Aj Ba|Fe|Pl|Ge 11 Atr _ _
11 ακτών ακτή No NoCm Fe|Pl|Ge 8 Atr _ _
12 της μου Pn PnPo Fe|03|Sg|Ge|Xx 11 Atr _ _
13 . . PUNCT PUNCT _ 0 AuxK _ _
1 Πιστεύω πιστεύω Vb VbMn Id|Pr|01|Sg|Xx|Ip|Av|Xx 0 Pred _ _
2 ότι ότι Cj CjSb _ 1 AuxC _ _
3 είναι είμαι Vb VbMn Id|Pr|03|Sg|Xx|Ip|Pv|Xx 2 Obj _ _
4 δίκαιο δίκαιο No NoCm Ne|Sg|Nm 3 Pnom _ _
5 να να Pt PtSj _ 7 AuxV _ _
6 το εγώ Pn PnPe Ne|03|Sg|Ac|We 7 Obj _ _
7 αναγνωρίσουμε αναγνωρίζω Vb VbMn Id|Xx|01|Pl|Xx|Pe|Av|Xx 3 Sb _ _
8 αυτό αυτός Pn PnDm Ne|03|Sg|Ac|Xx 7 Obj _ _
9 . . PUNCT PUNCT _ 0 AuxK _ _
1 Η ο At AtDf Fe|Sg|Nm 2 Atr _ _
Radio2text
FM2text
I want to use speech_recognition to transcribe speech from radio (FM, AM, FSK,...)
I made a test prototyping and here are the instructions

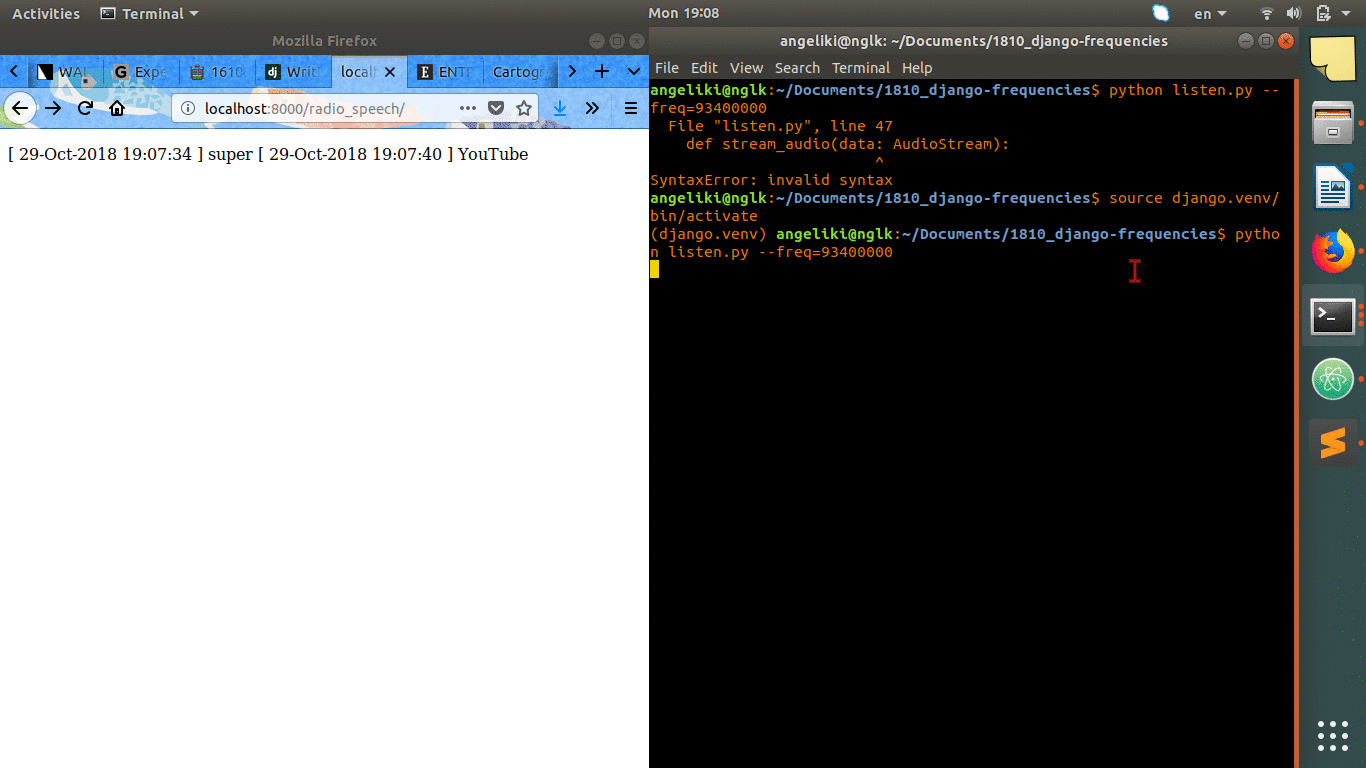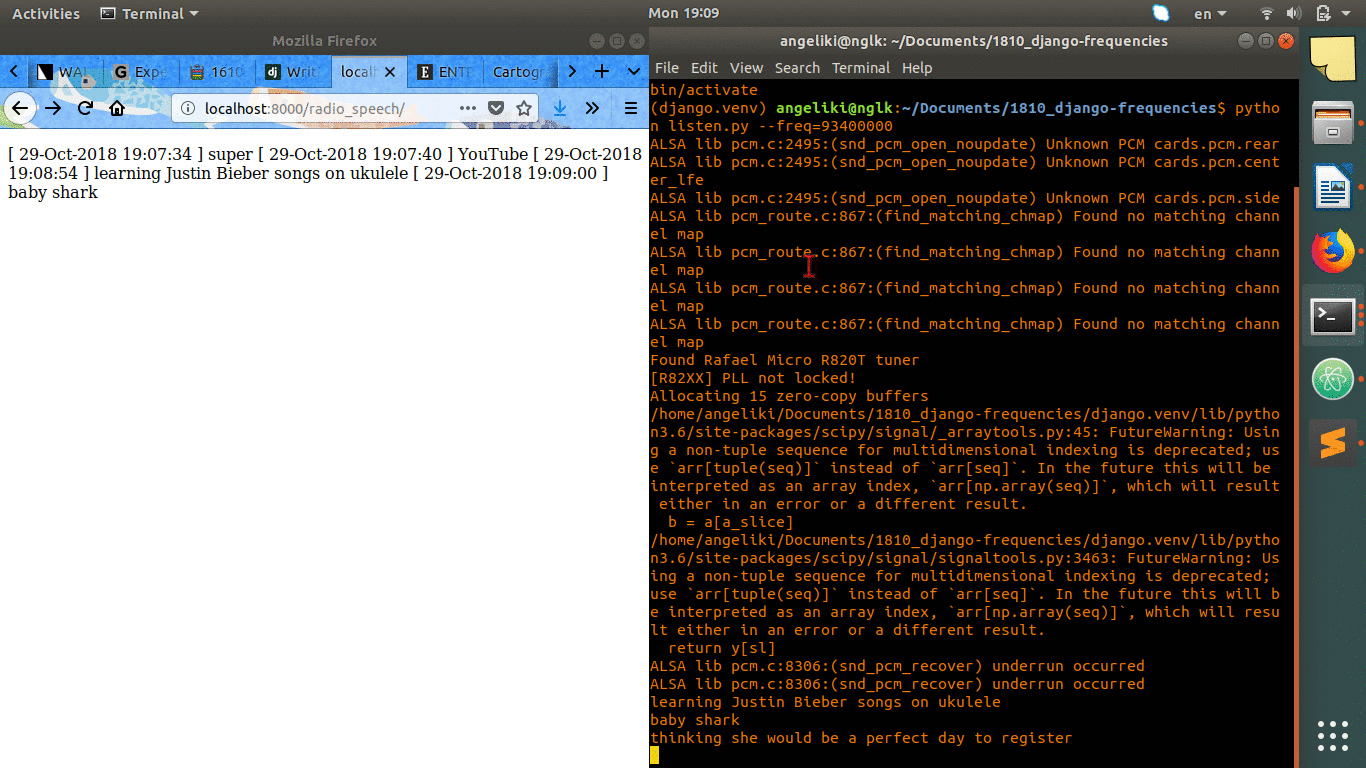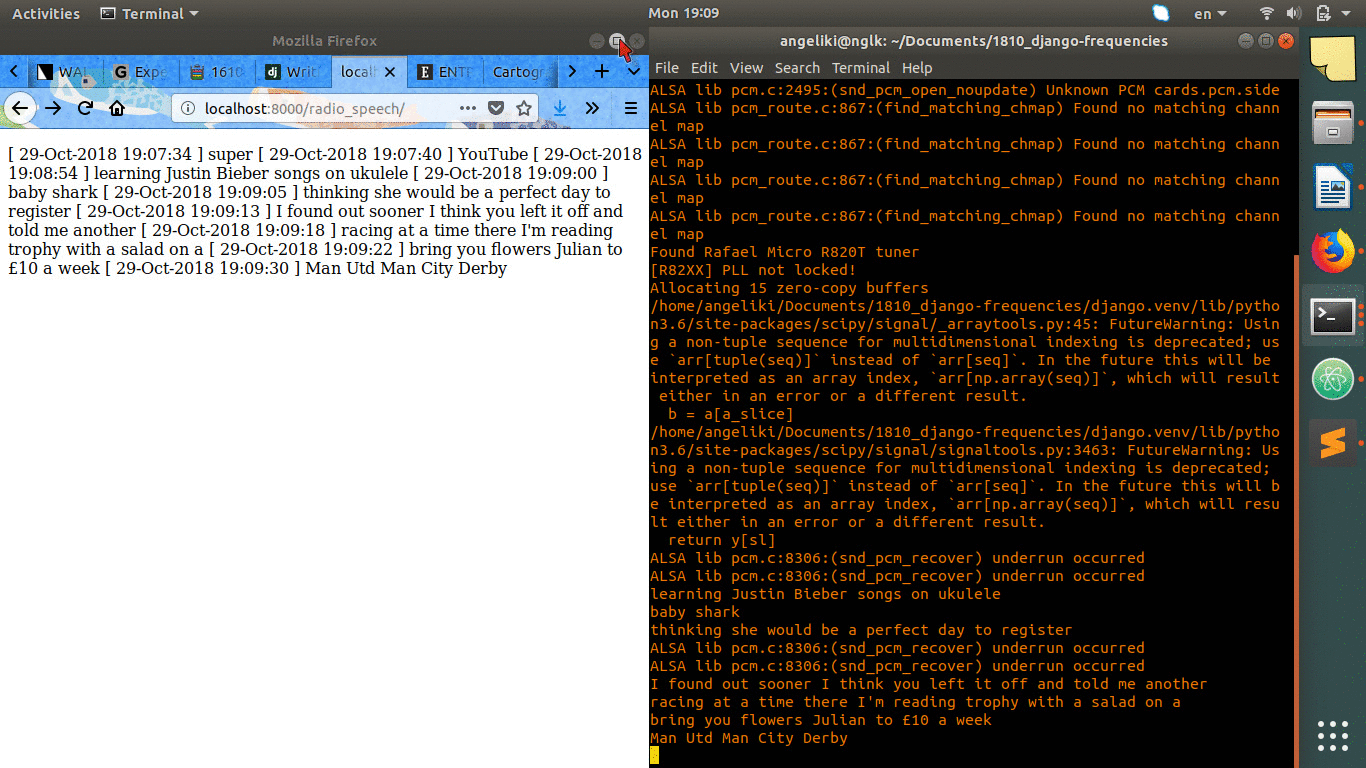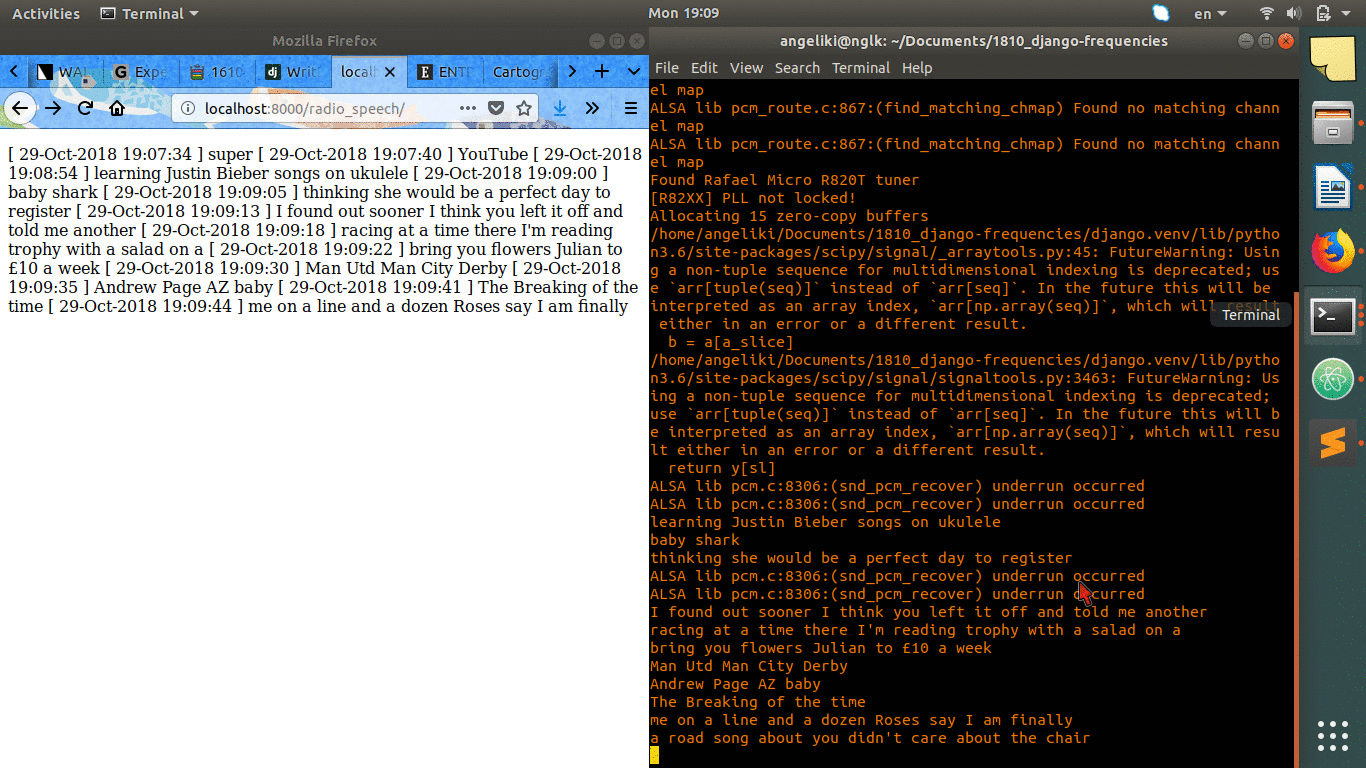
python listen.py --freq=93400000
from typing import List
from rtlsdr import RtlSdr
import argparse
import datetime
import numpy as np
import pyaudio
import scipy.signal as signal
import speech_recognition as sr
import threading
SampleStream = List[float]
AudioStream = List[int]
stream_buf = bytes()
stream_counter = 0
audio_rate = 48000
recognizer = sr.Recognizer()
audio_output = pyaudio.PyAudio().open(format=pyaudio.paInt16, channels=1, rate=audio_rate, output=True)
def recognize(stream_text):
global args
def logger(s):
f = open('radio_log.txt', 'a+', encoding='utf-8')
f.write(datetime.datetime.now().strftime("[ %d-%b-%Y %H:%M:%S ] "))
f.write(s)
f.write("\x0A")
f.close()
# print('sync')
audio_data = sr.AudioData(stream_text, audio_rate, 2)
try:
# result = recognizer.recognize_sphinx(audio_data)
result = recognizer.recognize_google(audio_data, language=args.lang)
print(result)
logger(result)
except sr.UnknownValueError:
pass
except sr.RequestError as e:
print("Could not request results from GSR service; {0}".format(e))
# print('done')
def stream_audio(data: AudioStream):
global args
global stream_buf
global stream_counter
if not args.verbose:
audio_output.write(data)
if stream_counter < args.buf:
stream_buf += data
stream_counter += 1
else:
threading.Thread(target=recognize, args=(stream_buf,)).start()
stream_buf = bytes()
stream_counter = 0
def process(samples: SampleStream, sdr: RtlSdr) -> None:
sample_rate_fm = 240000
iq_comercial = signal.decimate(samples, int(sdr.get_sample_rate()) // sample_rate_fm)
angle_comercial = np.unwrap(np.angle(iq_comercial))
demodulated_comercial = np.diff(angle_comercial)
audio_signal = signal.decimate(demodulated_comercial, sample_rate_fm // audio_rate, zero_phase=True)
audio_signal = np.int16(14000 * audio_signal)
stream_audio(audio_signal.astype("int16").tobytes())
def read_callback(samples, rtl_sdr_obj):
process(samples, rtl_sdr_obj)
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--ppm', type=int, default=0,
help='ppm error correction')
parser.add_argument('--gain', type=int, default=20,
help='RF gain level')
parser.add_argument('--freq', type=int, default=92900000,
help='frequency to listen to, in Hertz')
parser.add_argument('--lang', type=str, default='en-US',
help='language to recognize, en-US, ru-RU, fi-FI or any other supported')
parser.add_argument('--buf', type=int, default=100,
help='buffer size to recognize, 100 = 6.25 seconds')
parser.add_argument('--verbose', action='store_true',
help='mute audio output')
args = parser.parse_args()
sdr = RtlSdr()
sdr.rs = 2400000
sdr.fc = args.freq
sdr.gain = args.gain
sdr.err_ppm = args.ppm
sdr.read_samples_async(read_callback, int(sdr.get_sample_rate()) // 16)
FM2text/ Django
This prototyping is about live streaming the output of the speech recognition of radio speech into a web platform. I embedded the listen.py from the previous experiment to a django infrastructure. The output of the script, which is a logfile, is being shown and updated in a url of my instance in django.
[ 29-Oct-2018 19:07:34 ] super [ 29-Oct-2018 19:07:40 ] YouTube [ 29-Oct-2018 19:08:54 ] learning Justin Bieber songs on ukulele [ 29-Oct-2018 19:09:00 ] baby shark [ 29-Oct-2018 19:09:05 ] thinking she would be a perfect day to register [ 29-Oct-2018 19:09:13 ] I found out sooner I think you left it off and told me another [ 29-Oct-2018 19:09:18 ] racing at a time there I'm reading trophy with a salad on a [ 29-Oct-2018 19:09:22 ] bring you flowers Julian to £10 a week [ 29-Oct-2018 19:09:30 ] Man Utd Man City Derby [ 29-Oct-2018 19:09:35 ] Andrew Page AZ baby [ 29-Oct-2018 19:09:41 ] The Breaking of the time [ 29-Oct-2018 19:09:44 ] me on a line and a dozen Roses say I am finally [ 29-Oct-2018 19:09:50 ] a road song about you didn't care about the chair [ 29-Oct-2018 19:09:55 ] all I wanted was for you to keep it in your house bring you down [ 29-Oct-2018 19:10:02 ] do you do Stefan and Daily Mail [ 29-Oct-2018 19:10:07 ] Lowdham caravans [ 29-Oct-2018 19:10:12 ] compromise [ 29-Oct-2018 19:10:18 ] young drivers to your doorstep undertale [ 29-Oct-2018 19:10:23 ] plane crazy Argos [ 29-Oct-2018 19:10:31 ] are you ok baby [ 29-Oct-2018 19:10:35 ] sorry
//index.html
<!DOCTYPE html>
<html lang="en" dir="ltr">
<head>
<meta charset="utf-8">
<title></title>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script>
</head>
<body>
<p id='text'></p>
<script>
function sendRequest(){
$.ajax({
url: "http://localhost:8000/radio_speech/draft",
method: "GET",
success:
function(result){
// console.log('ss'); //check if it is working in the console
$('#text').text(result); //insert text of test.php into your div
setTimeout(function(){
sendRequest(); //this will send request again and again;
}, 5000);
}
});
}
sendRequest();
</script>
</body>
</html>
NEXT: scanning through several frequencies and speech recognition
Pirates speech to text

Collect radio sounds
An attempt to collect radio sounds depending on what text accompanies them, on time, on frequencies or other factors. For example every time the software listens to streaming and recognizes a sound of voice (300 and 3000 Hz) or a word then it records down/collects.
Antennas
