
User:Artemis gryllaki/PrototypingIII: Difference between revisions
No edit summary |
No edit summary |
||
| (29 intermediate revisions by the same user not shown) | |||
| Line 1: | Line 1: | ||
==Publishing an “image gallery”== | ==Publishing an “image gallery”== | ||
'''Imagemagick'''’s suite of tools includes montage which is quite flexible and useful for making a quick overview page of image. | |||
* mogrify | * mogrify | ||
| Line 8: | Line 8: | ||
Warning: MOGRIFY MODIES THE IMAGES – ERASING THE ORIGINAL – make a copy of the images before you do this!!!<br><br> | Warning: MOGRIFY MODIES THE IMAGES – ERASING THE ORIGINAL – make a copy of the images before you do this!!!<br><br> | ||
==Montages== | |||
[[File:montage-try.png | 500px | thumbnail | left | Workshop Images|link=]] | |||
[[File:montage-try3.png | 500px | thumbnail | center | Workshop Images|link=]] | |||
<br clear=all> | |||
'''poster.py!''' | |||
<source lang="python"> | |||
#!/usr/bin/env python3 | |||
import os, datetime, sys | |||
from argparse import ArgumentParser | |||
from glob import glob | |||
import os | |||
os.system('imagemagick-converting-command filein fileout') | |||
from PIL import Image | |||
from reportlab.pdfgen import canvas | |||
from reportlab.lib.pagesizes import A0 | |||
# p = ArgumentParser("") | |||
# p.add_argument("--output", default="poster.pdf") | |||
# p.add_argument("--interpolation", default="cubic", help="nearest,cubic") | |||
# p.add_argument("--labels", default="labels_public.txt") | |||
# args = p.parse_args() | |||
pagewidth, pageheight = A0 | |||
c = canvas.Canvas("reportlab_image_poster2.pdf", pagesize=A0) | |||
x, y = 0, 0 | |||
imagewidth = 200 | |||
imageheight = 300 | |||
aw = pagewidth - imagewidth | |||
ah = pageheight - imageheight | |||
images = (glob ("images/*.JPG")) | |||
dx = aw/(len(images)-1) | |||
dy = ah/(len(images)-1) | |||
for image in images: | |||
print ("Adding an image to the PDF") | |||
print (image) | |||
im = Image.open(image) | |||
pxwidth, pxheight = im.size | |||
print ("Got the image, it's size is:", im.size) | |||
imageheight = imagewidth * (pxheight / pxwidth) | |||
c.drawInlineImage(image, x, y, imagewidth, imageheight) | |||
print ("placing image {0} at {1}".format(image, (x,y))) | |||
x += dx | |||
y += dy | |||
c.showPage() | |||
c.save() | |||
sys.exit(0) | |||
################# | |||
# GRID | |||
# imsize = 96 | |||
# cols = int(A0[0] // imsize) | |||
# rows = int(A0[1] // imsize) | |||
# # calculate margins to center the grid on the page | |||
# mx = (A0[0] - (cols*imsize)) / 2 | |||
# my = (A0[1] - (rows*imsize)) / 2 | |||
# print ("Grid size {0}x{1} (cols x rows)".format(cols, rows)) | |||
# print (" (total size:", cols*imsize, rows*imsize, "margins:", mx, my, ")") | |||
################# | |||
# for l in range(7): | |||
# print (LABELS[l]) | |||
# col = 0 | |||
# row = 0 | |||
# with open(args.labels) as f: | |||
# f.readline() | |||
# for line in f: | |||
# path, label = line.split(",") | |||
# label = int(label) | |||
# if label == l: | |||
# image = Image.open(path) | |||
# print (image.size) | |||
# x = mx + (col*imsize) | |||
# y = my + imsize + (7-l)*(4*imsize) - ((row+1)*imsize) | |||
# c.drawInlineImage(image, x, y, width=imsize, height=imsize) | |||
# col += 1 | |||
# if col >= cols: | |||
# col = 0 | |||
# row +=1 | |||
# if row >= 3: | |||
# break | |||
# c.showPage() | |||
< | # c.save() | ||
</source> | |||
== OCR | Optical character recognition with Tesseract== | |||
In command line: tesseract nameofpicture.png outputbase<br><br> | |||
< | |||
< | |||
=== | [[File:scan_source.png | 500px | thumbnail | left | Scanning a book page|link=]] | ||
[[File:ocr_output.png | 500px | thumbnail | center | Output: character recognition with tesseract-ocr / styled with javascript |link=]]<br clear=all> | |||
[[File:Screenshot2.png | 500px | thumbnail | left |link=]] | |||
[[File:Screenshot3.png | 500px | thumbnail | center |link=]]<br clear=all> | |||
== Blurry Boundaries Workshop == | |||
[[File: | [[File:blurry1.png | 400px | thumbnail | left |Scanning a book page|link=]] | ||
[[File:blurry2.png | 400px | thumbnail | left |OCR-ing the book page|link=]] | |||
[[File:blurry3.png | 800px | thumbnail | center |My hidden labour|link=]] | |||
Latest revision as of 21:36, 8 July 2019
Publishing an “image gallery”
Imagemagick’s suite of tools includes montage which is quite flexible and useful for making a quick overview page of image.
- mogrify
- identify
- convert
- Sizing down a bunch of images
Warning: MOGRIFY MODIES THE IMAGES – ERASING THE ORIGINAL – make a copy of the images before you do this!!!
Montages

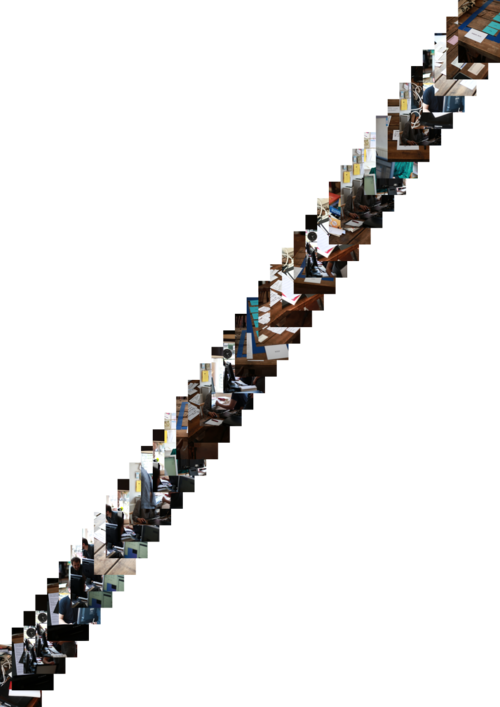
poster.py!
#!/usr/bin/env python3
import os, datetime, sys
from argparse import ArgumentParser
from glob import glob
import os
os.system('imagemagick-converting-command filein fileout')
from PIL import Image
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import A0
# p = ArgumentParser("")
# p.add_argument("--output", default="poster.pdf")
# p.add_argument("--interpolation", default="cubic", help="nearest,cubic")
# p.add_argument("--labels", default="labels_public.txt")
# args = p.parse_args()
pagewidth, pageheight = A0
c = canvas.Canvas("reportlab_image_poster2.pdf", pagesize=A0)
x, y = 0, 0
imagewidth = 200
imageheight = 300
aw = pagewidth - imagewidth
ah = pageheight - imageheight
images = (glob ("images/*.JPG"))
dx = aw/(len(images)-1)
dy = ah/(len(images)-1)
for image in images:
print ("Adding an image to the PDF")
print (image)
im = Image.open(image)
pxwidth, pxheight = im.size
print ("Got the image, it's size is:", im.size)
imageheight = imagewidth * (pxheight / pxwidth)
c.drawInlineImage(image, x, y, imagewidth, imageheight)
print ("placing image {0} at {1}".format(image, (x,y)))
x += dx
y += dy
c.showPage()
c.save()
sys.exit(0)
#################
# GRID
# imsize = 96
# cols = int(A0[0] // imsize)
# rows = int(A0[1] // imsize)
# # calculate margins to center the grid on the page
# mx = (A0[0] - (cols*imsize)) / 2
# my = (A0[1] - (rows*imsize)) / 2
# print ("Grid size {0}x{1} (cols x rows)".format(cols, rows))
# print (" (total size:", cols*imsize, rows*imsize, "margins:", mx, my, ")")
#################
# for l in range(7):
# print (LABELS[l])
# col = 0
# row = 0
# with open(args.labels) as f:
# f.readline()
# for line in f:
# path, label = line.split(",")
# label = int(label)
# if label == l:
# image = Image.open(path)
# print (image.size)
# x = mx + (col*imsize)
# y = my + imsize + (7-l)*(4*imsize) - ((row+1)*imsize)
# c.drawInlineImage(image, x, y, width=imsize, height=imsize)
# col += 1
# if col >= cols:
# col = 0
# row +=1
# if row >= 3:
# break
# c.showPage()
# c.save()
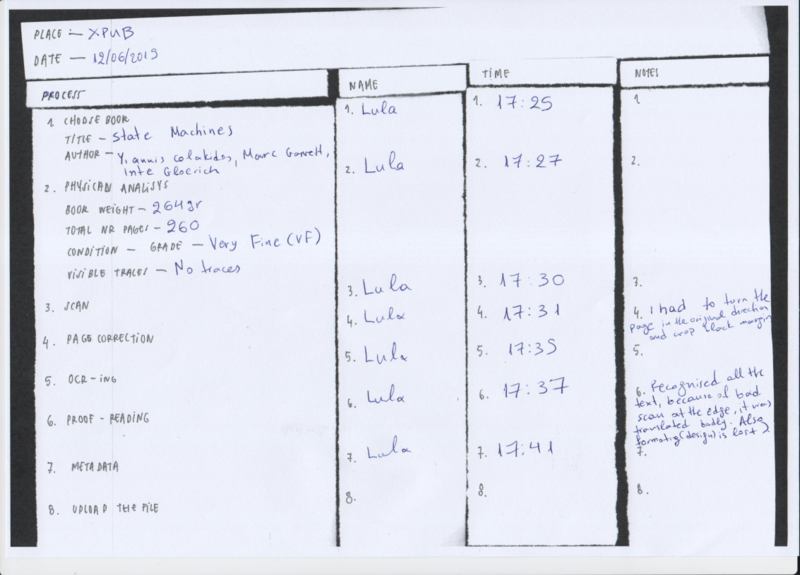
OCR | Optical character recognition with Tesseract
In command line: tesseract nameofpicture.png outputbase






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}