
User:Alice/XPPL: Difference between revisions
No edit summary |
|||
| (2 intermediate revisions by the same user not shown) | |||
| Line 1: | Line 1: | ||
=== Stacks === | === Stacks === | ||
== Theoretical approach == | == Theoretical approach == | ||
| Line 78: | Line 80: | ||
</onlyinclude> | </onlyinclude> | ||
==Working with databases== | |||
===Creating a search engine based on tf-idf=== | |||
[[File:Pmgoogle3.png]] | |||
{{User:Alice/IFL}} | |||
== To continue == | |||
A couple of points I would like to work on further: | |||
* helping to maintain this library and make the database more stable | |||
* add new features to stacks - group stacks under the name of the author, consider ways to visualize relationships between stacks | |||
* allow bulk downloading for books in stacks | |||
* adding collections vs adding individual books - thinking in stacks prior to the upload | |||
Latest revision as of 10:17, 15 June 2018
Stacks
Theoretical approach
The concept of stacks relies on a combination of two meta-theories in information science– collectivism (social constructivism) and constructionism. In broad terms, this means that the emphasis within the concept of the stack is on discourse as knowledge production, social understandings of knowledge and the knowledge as a product of thought-collectives.
When building a stack, one can think of a particular project she was involved in. In the process of working on that project, references built up from many different sources, some contradictory, some irrelevant at first glance, but ultimately useful in creating a broad view around the topic of research. The community the researcher is part of has a major influence in building the reference points that are being accessed within the research. All information that circulates around this particular project is reconstructed in the idea of a stack of books kept beside the bed, one that is consulted often, with books browsed at random when needed.
As Marcia Bates references in her paper on digital libraries, ‘The user’s experience is phenomenologically different from the indexer’s experience. The user ’s task is to describe something that, by definition, he or she does not know (Belkin, 1982)’. What is more, as Harter (1992) points out, discovering that a particular article is relevant to one’s concerns does not necessarily mean that the article is ‘about’ the same subject as one’s originating interest. Generally, catalogers do not index on the basis of these infinitely many possible anticipated needs. T rying to combine both of these experiences made me realize why elements such as stack description, other books in the stack, links between stacks and annotations are so necessary. They are there to guide the reader to the desired topic without necessarily knowing exactly what she is looking for.
Implementation

Adding a new stack
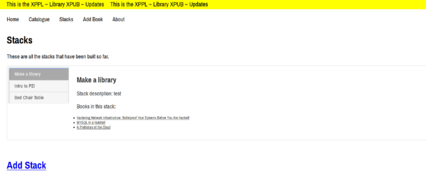
An overview of all the stacks
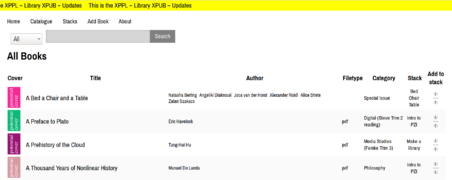
Adding a book to a stack
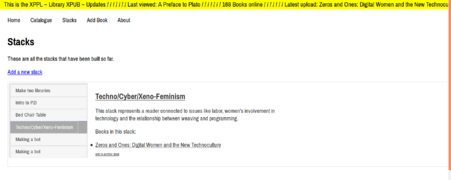
Adding a book in a stack to another stack
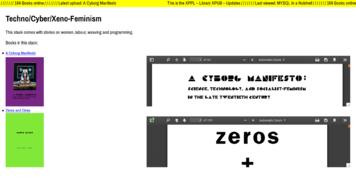
A stack of books

Updated version






Conected research
Git branches
When you create a branch within a project in git, you diverge from the main line of development and continue working on a a separate line without affecting the main line. A branch is a movable pointer to one of the snapshots of your project (a commit).

Setting up
To create a new branch, you first have to go to the folder in which you cloned the git repository.
- Check your current status and branch:
git status
git branch -v
- To create a new branch:
git branch name_of_branch
or
git checkout -b name_of_branch
which creates a new branch and moves you inside it
otherwise, to go inside your new branch
git checkout name_of_branch
Now you can start working on your new branch and commiting to it.
Merging the branches
First, move to the main branch and get the latest version, in case other people have pushed their commits to it in the meantime.
checkout master
to see the difference between your version of the master branch and the current version:
git status
git diff
now pull, and resolve conflicts if there are any:
pull origin master
In order to merge both branches, you can use the rebase command to put your latest commits on top of all other commits in the master branch. Then, fix any conflicts that might occur in your text editor, add the changed files, commit, merge and push.
git checkout name_of_branch
git rebase master
fix conflicts
git add name_of_changed_files
git checkout master
git merge name_of_branch
git push origin master
Research questions: If computers made book synopses, or were in charge of categorizing books using the Dewey Decimal Classification, how would they weigh up against humans in making these decisions?
Markov Chains
Markov chains are used to create statistical models of the sequences of letters in a text. Markov chains are now widely used in speech recognition, handwriting recognition, information retrieval, data compression, and spam filtering.

Using a fork of a Markov text generator script (listed below) I generated abstracts of various texts and analyzed the results.
Example 1
Original text: When Computers Were Women, by Jennifer Light
Abstract:
ved credit for innovation or invention. The story presents an apparent paradox. It suggests that women from the history while the way women were breaking into traditionally male occupations during World War II. These two talented engineering.
A closer look at this literature explicates the paradox by revealing wide spread ambivalence about women from the history of ENIAC's female computations during this stage of computers," performing ballistics computations as subprofessional. While celebrating women's work. While celebrated than their own.
The omission of labor. The story of ENIAC's "invention" with special focus on the female computer science perpetuates misconceptions of them were selected to programmer, perceived credit for innovation or invention.
The story of computer, ENIAC, to automate ballistics computers supports Ruth Milkman's thesis of an "idiom of sex-typing" during this stage of computations during the difficulty of these women with mathematical training were ass
Notes
- This text has been OCRd from a scan, so the text quality is not perfect, hence the occasional fragments of words.
Example 2
Original text: A news article on AlJazeera
Abstract:
The government's "Yes" camp. The call for an early polls.
The government has asked parliamentary and presidential polls had previously been slated for snap election. Earlier this year, his ruling Justice and Development Party (AK Party), reached an elections would begin. His comments came after meeting Devlet Bahceli's MHP. State of emergency that will increase the powers to appoint vice president new powers to appoint vice presidential election comes as nationalist Movement led by US-based cleric Fethullah Gulen, whom Turkey's continued struggle against Kurdish fighters as "terror threats from a northern enclave.
Erdogan said.
Ankara has labeled the prospect of early polls.
The constitutional changed in an April 2017 referendum that will increase the powers to appoint vice presidential system needs to be confirmed by the elections to be re-elected in the vote give the next president. The snap election commission, he said, but preparations would begin.
Resources
- https://kgullikson88.github.io/blog/markov-chain.html
- https://xiaoxu193.github.io/PyTeaser/
- https://github.com/alicestrt/MarkovTextGenerator (only one that works for me so far)
Working with databases
Creating a search engine based on tf-idf

My contribution to Xpub Library
Research questions
- How can we represent the books in the collection in a different way - using the idea of stacks as mixtapes, depending on study path and reading time
- What kind of interface would be best suited for a library that serves our community
Knowledge organization
Examples Stacks A stack is a number of books that are read at a certain point in time, alternating between them. They usually have a topic in common, or follow a certain study path that can bring you to a point of knowledge. Rather than a bookshelf, where books are lined up and often forgotten, the stack on your table/nightstand/toilet consists of books prone to be opened and reopened at any time.
Reading time
For this first challenge, I looked into representing a text through the amount of time it takes to read (similar to Medium). I adapted this script (license) using BeautifulSoup to extract the text from an html file and print out the estimated reading time in minutes and hours.
import bs4
import urllib.request, re
from math import ceil
def extract_text(url):
html = urllib.request.urlopen(url).read()
soup = bs4.BeautifulSoup(html, 'html.parser')
texts = soup.findAll(text=True)
return texts
def is_visible(element):
if element.parent.name in ['style', 'script', '[document]', 'head', 'title']:
return False
elif isinstance(element, bs4.element.Comment):
return False
elif element.string == "\n":
return False
return True
def filter_visible_text(page_texts):
return filter(is_visible, page_texts)
WPM = 180
WORD_LENGTH = 5
def count_words_in_text(text_list, word_length):
total_words = 0
for current_text in text_list:
total_words += len(current_text)/word_length
return total_words
def estimate_reading_time(url):
texts = extract_text(url)
filtered_text = filter_visible_text(texts)
total_words = count_words_in_text(filtered_text, WORD_LENGTH)
minutes = ceil(total_words/WPM)
hours = minutes/60
return [minutes, hours]
html_file = 'file:///home/alice/Documents/Reader%20final/txt/where_is.html'
values = estimate_reading_time(html_file)
print('It will take you', values[0], ' minutes or', values[1], 'hours to read this text')
Interface
I want to research the prospect of having only a command line interface through which anyone can search the library, shared online using gotty.
Things I'm currently playing with:
Syncthing testing
Syncthing
Session with Tash, Andre & Alice: 28.05.2018
How to configure and install syncthing on the raspberry pi, and two of our own machines?
Syncthing can be used to sync book files and catalog files between different instances of our library (e.g. syncing catalog between server and Pi's, syncing book files between Pi's)
Files are not stored in the cloud and it allows for decentralized, read-write architecture (different from rsync which uses a master-slave relationship)
Running Syncthing
At first start Syncthing will generate a configuration file, some keys and then start the admin GUI in your browser.
The GUI remains available on https://localhost:8384/.
For Syncthing to be able to synchronize files with another device, it must be told about that device. This is accomplished by exchanging “device IDs”. A device ID is a unique, cryptographically-secure identifier that is generated as part of the key generation the first time you start Syncthing. It is printed in the log above, and you can see it in the web GUI by selecting the “gear menu” (top right) and “Show ID”.
Two devices will only connect and talk to each other if they are both configured with each other’s device ID. Since the configuration must be mutual for a connection to happen, device IDs don’t need to be kept secret. They are essentially part of the public key.
To get your two devices to talk to each other click “Add Device” at the bottom right on both, and enter the device ID of the other side. You should also select the folder(s) that you want to share. The device name is optional and purely cosmetic. It can be changed later if required.
Configuration
Syncthing config.xml file, which can be edited via terminal or through the web GUI interface.
Each element describes one folder. The following attributes may be set on the folder element:
id - The folder ID, must be unique. (mandatory)labelThe label of a folder is a human readable and descriptive local name. May be different on each device, empty, and/or identical to other folder labels. (optional)
path - The path to the directory where the folder is stored on this device; not sent to other devices. (mandatory)
type - Controls how the folder is handled by Syncthing. Possible values are:
readwrite - The folder is in default mode. Sending local and accepting remote changes.readonlyThe folder is in “send-only” mode – it will not be modified by Syncthing on this device.
rescanIntervalS - The rescan interval, in seconds. Can be set to zero to disable when external plugins are used to trigger rescans.
Because the pi can't access the browser GUI, you can change the config file to add the GUI port address from 127... to 0000 served on Apache web server. Then you can look at the GUI remotely in your browser. Alternatively, you can add device keys via terminal in the config file. Question: Can we have rw permissions on the main pi, and read only permissions on all others? - probs

Troubleshooting
Kernel Panic
Don't use the shark SD card! Aymeric bought them for super cheap and they will corrupt the f up.
Kernel panic means you have to try and reboot the Pi in recovery mode. Or... abort.
Merging & file conflicts
Editing CSV files in different nodes at the same time will result in conflicts.
How to make a fault tolerant, decentralized file system which will allow up-to-date uploads, edits and deletions between different nodes?
Important for us: How to keep catalog and files separate so that only catalog is visible to public? AND How to make sure file and catalog are synced in a way that is distributed?
Wishlist
To continue
A couple of points I would like to work on further:
- helping to maintain this library and make the database more stable
- add new features to stacks - group stacks under the name of the author, consider ways to visualize relationships between stacks
- allow bulk downloading for books in stacks
- adding collections vs adding individual books - thinking in stacks prior to the upload