User:Francg/expub/thesis/hackpackt: Difference between revisions
No edit summary |
No edit summary |
||
| (2 intermediate revisions by the same user not shown) | |||
| Line 14: | Line 14: | ||
- Install "Twarc" to extract content updated content from Twitter | - Install "Twarc" to extract content updated content from Twitter | ||
<br>- Install "Feedme" to create RSS for any website that doesn't provide it (it can monitor Facebook groups) | <br>- Install "Feedme" to create RSS for any website that doesn't provide it (it can monitor Facebook groups but not single users) | ||
<br>- Try to monitor with diffengine these new RSS created with feedme, so we can see their content | <br>- Try to monitor with diffengine these new RSS feed created with feedme, so we can see their content changing. | ||
<br>- Convert autom html files to txt files using python, as they happen to be created by diffengine | <br>- Convert autom html files to txt files using python, as they happen to be created by diffengine | ||
<br>- Use Python + Beautiful Soup to count specific words from txt file and extract a list of most used. | <br>- Use Python + Beautiful Soup to count specific words from txt file and extract a list of most used. | ||
<br>- | <br>- Use Python + Beautiful Soup to count number of changes. | ||
<br>- Compare ranking words & changes on each txt file (rss feed article). Maybe this table can be updated automatically? | <br>- Compare ranking words & changes on each txt file (rss feed article). Maybe this table can be updated automatically? | ||
<br>- Install raspberry pi | <br>- Install raspberry pi | ||
<br>- Create a database | <br>- Create a database (MongoDB or SQL like databases), small forms, javascript snippets, etc. Example: "Wikileaks" structure | ||
<br>- Database offers access to raw materials/content, and to additional features such as collaborations from invited figures (they could be essays, articles, comments, interviews, a peace of code, or anything really). | |||
<br>- Find these collaborations (e.g."Arxivem el moment", "docnow", 1-O computer scientists, social organizations, ONGs, independent journalists, politicians, students, newspaper directors in relation to specific news,...) | |||
<br>- Upload files to this database autom as they happen to be created by diffengine | <br>- Upload files to this database autom as they happen to be created by diffengine | ||
<br>- Design database! | |||
<br>- Use onion browser like Tor to keep the users and the database IP protected from online surveillance, and as a way to reinforce and support freedom of speech against network censorship from state power. | |||
== == | == == | ||
<br> | <br> | ||
| Line 31: | Line 36: | ||
<br>[[File:Difftest1.png|1,696 × 1113 px|thumb|left|rssfeed-elperiodico]] | <br>[[File:Difftest1.png|1,696 × 1113 px|thumb|left|rssfeed-elperiodico]] | ||
<br><br><br><br><br><br><br><br><br><br><br><br> | <br><br><br><br><br><br><br><br><br><br><br><br> | ||
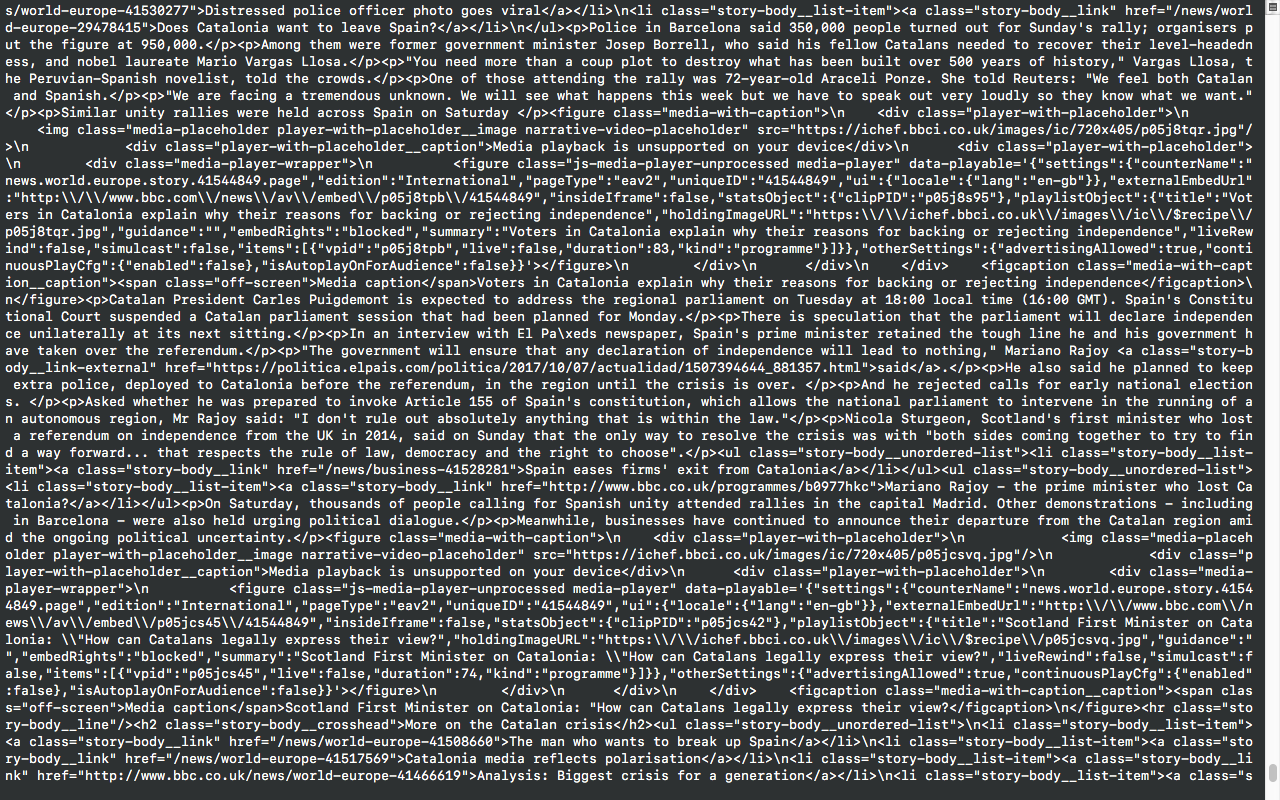
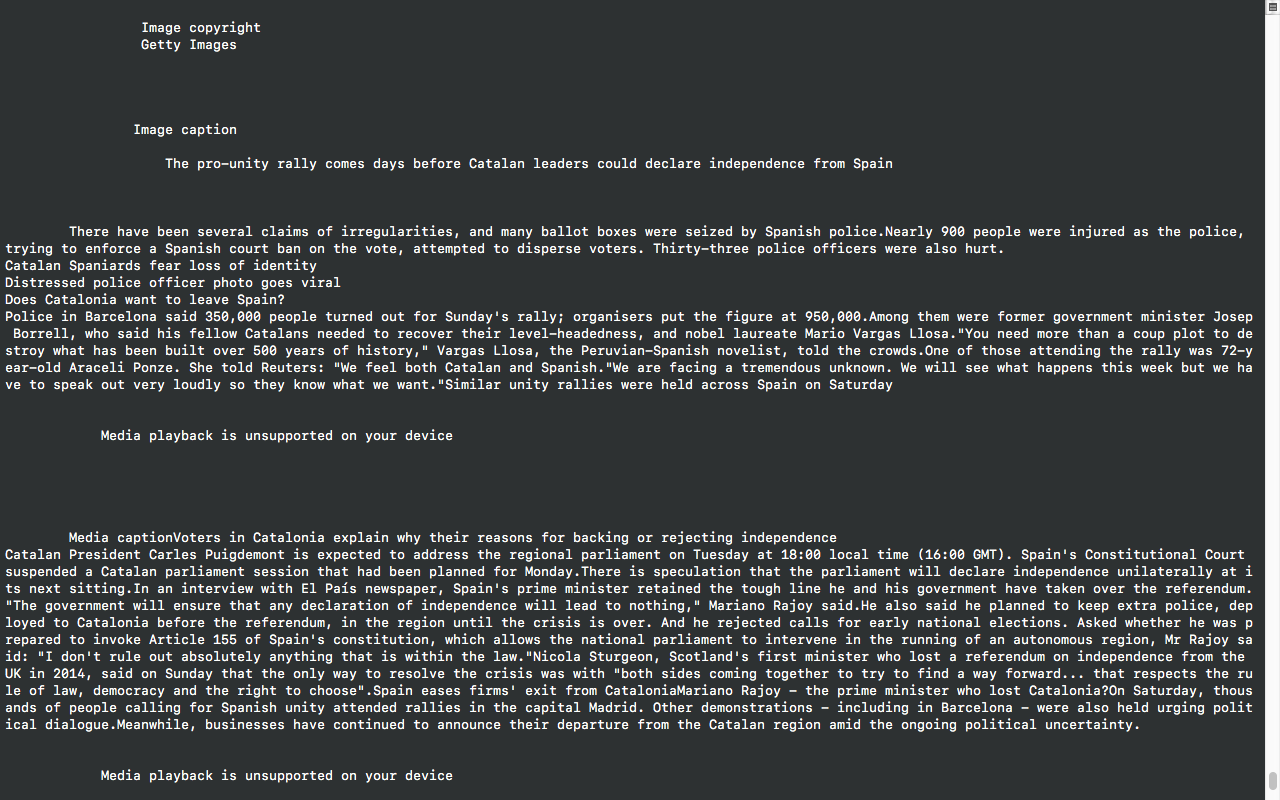
What RSS/Atom feed | What RSS/Atom feed would you like to monitor? | ||
<br>Would you like to set up tweeting edits? [Y/n] | <br>Would you like to set up tweeting edits? [Y/n] | ||
Latest revision as of 20:42, 24 October 2017
Diffengine prototypes
- Installing Diffengine
- Selecting RSS news feed (online journalism)
- Configuring diffengine to check out feeds every 5 min
- Monitor RSS feeds and download content changes (if there are) as jpg & html
Forthcoming prototypes:
- Install "Twarc" to extract content updated content from Twitter
- Install "Feedme" to create RSS for any website that doesn't provide it (it can monitor Facebook groups but not single users)
- Try to monitor with diffengine these new RSS feed created with feedme, so we can see their content changing.
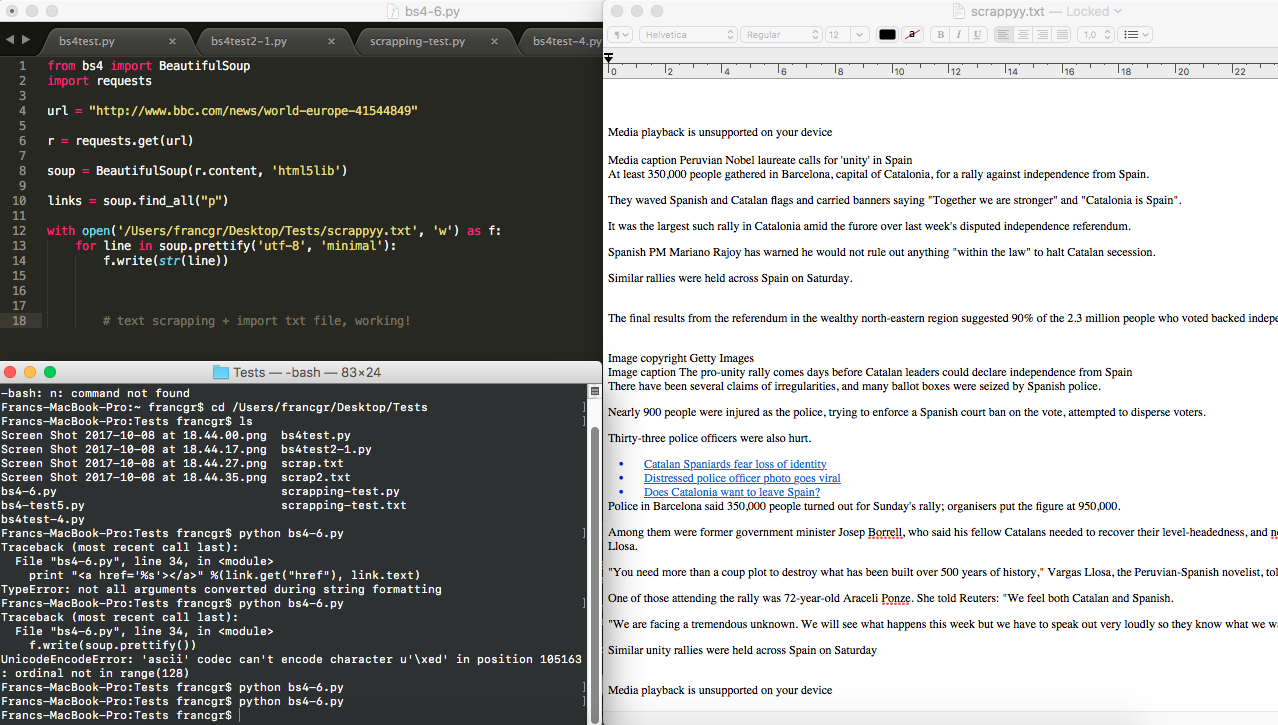
- Convert autom html files to txt files using python, as they happen to be created by diffengine
- Use Python + Beautiful Soup to count specific words from txt file and extract a list of most used.
- Use Python + Beautiful Soup to count number of changes.
- Compare ranking words & changes on each txt file (rss feed article). Maybe this table can be updated automatically?
- Install raspberry pi
- Create a database (MongoDB or SQL like databases), small forms, javascript snippets, etc. Example: "Wikileaks" structure
- Database offers access to raw materials/content, and to additional features such as collaborations from invited figures (they could be essays, articles, comments, interviews, a peace of code, or anything really).
- Find these collaborations (e.g."Arxivem el moment", "docnow", 1-O computer scientists, social organizations, ONGs, independent journalists, politicians, students, newspaper directors in relation to specific news,...)
- Upload files to this database autom as they happen to be created by diffengine
- Design database!
- Use onion browser like Tor to keep the users and the database IP protected from online surveillance, and as a way to reinforce and support freedom of speech against network censorship from state power.
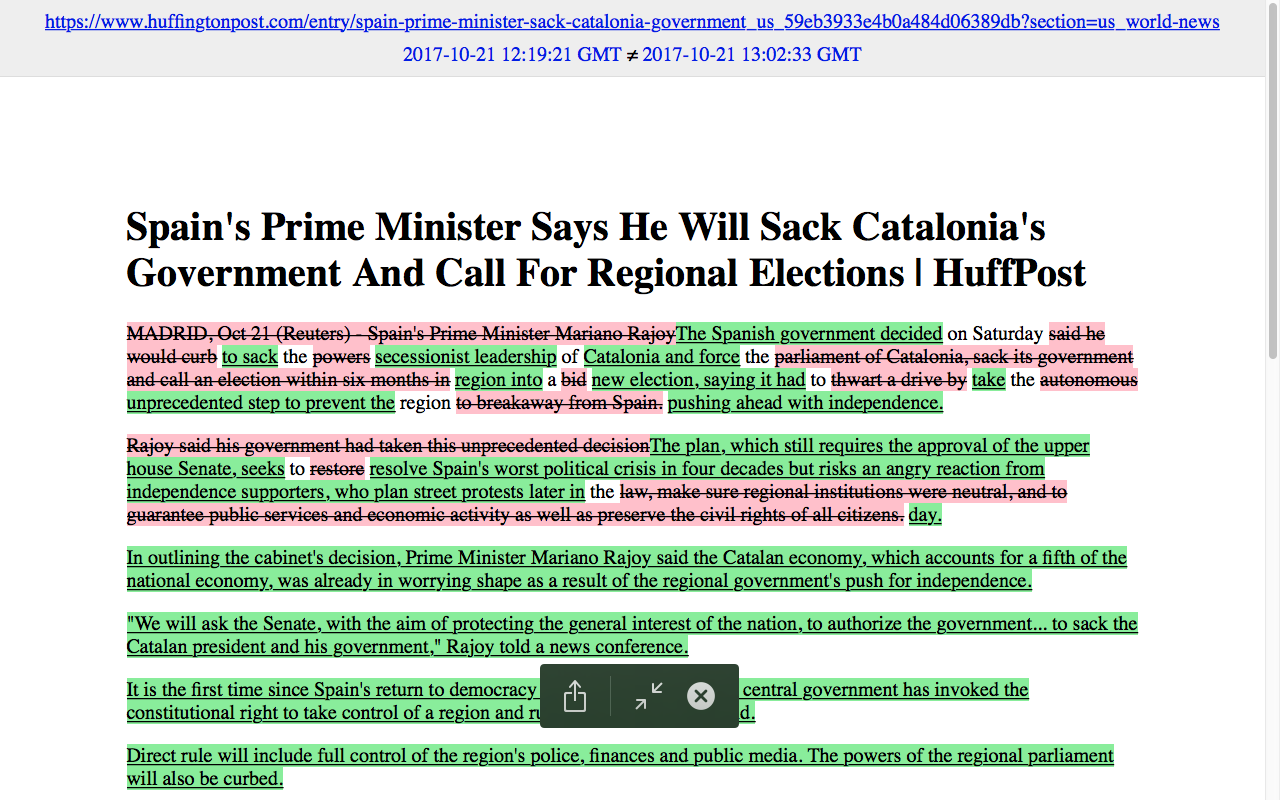
RSS Feed Hunginfton post

What RSS/Atom feed would you like to monitor?
Would you like to set up tweeting edits? [Y/n]

rundiff.sh (paths to each news feed in device)> config.yaml (RSS feed to phantomjs path) > folders (where input data is stored)> files (jpg & html)
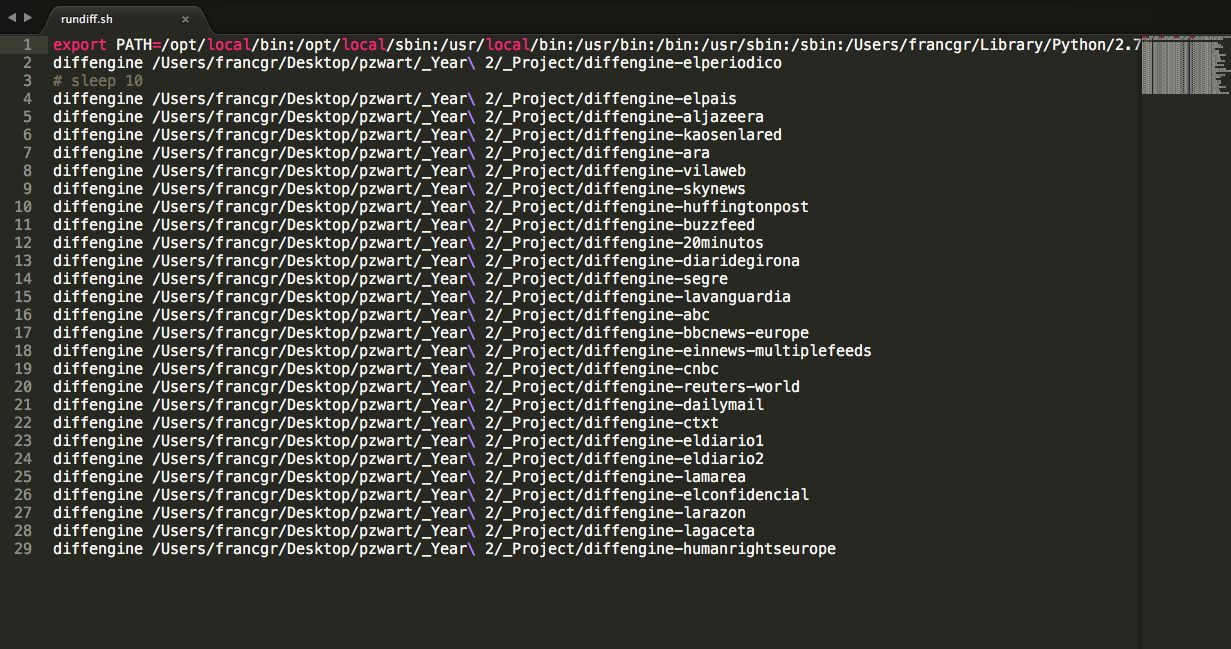
rundiff.sh: sources monitoring, and path to device
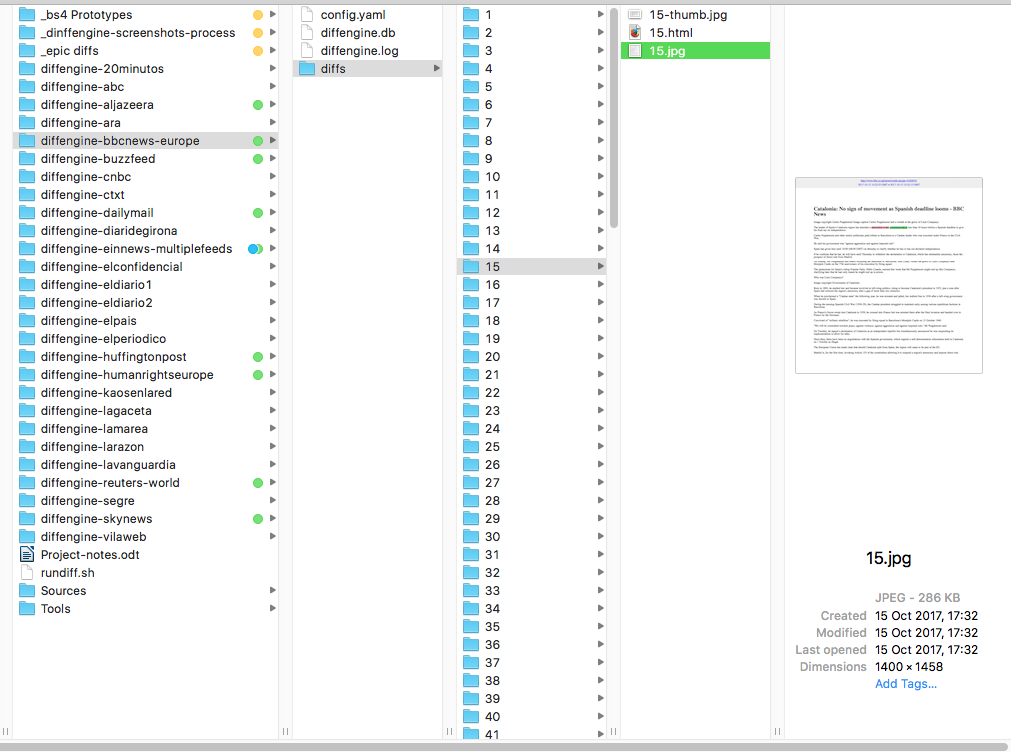
rss newsfeed folders where jpg & html files are created
"You have mail" in Terminal
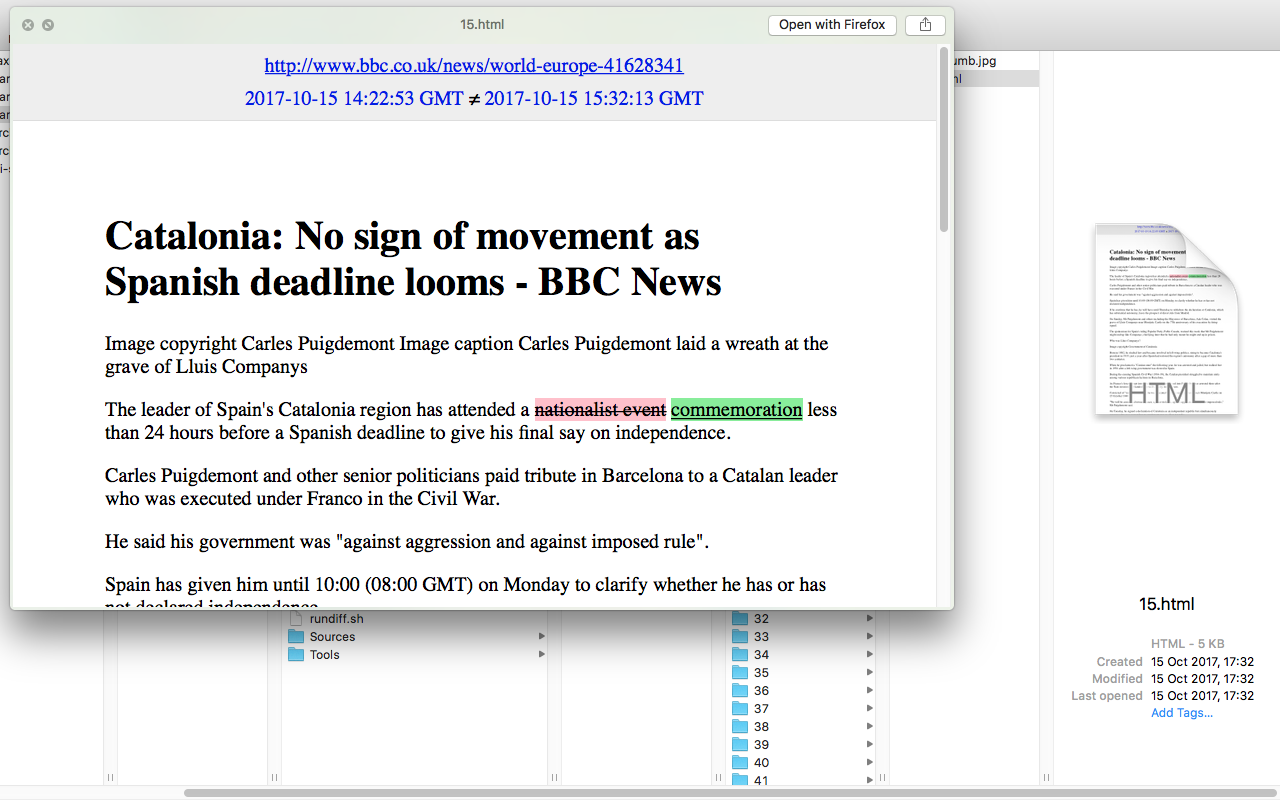
bbcnews
huffingtonpost

















Beautiful Soup prototypes: Extracting structured content and output to txt file