User:Francg/expub/thesis/prototype: Difference between revisions
No edit summary |
No edit summary |
||
| Line 24: | Line 24: | ||
<br> print(link.get('href')) | <br> print(link.get('href')) | ||
Bs4-test-reddit1-2.png | |||
<img src="https://pzwiki.wdka.nl/mw-mediadesign/images/9/98/Bs4-test-reddit1.png" alt="Bs4-test-reddit1" width="250%" height="250%"/> | |||
<img src="https://pzwiki.wdka.nl/mw-mediadesign/images/9/ | <img src="https://pzwiki.wdka.nl/mw-mediadesign/images/5/56/Bs4-test-reddit1-2.png" alt="Bs4-test-reddit1-2" width="250%" height="250%"/> | ||
<img src="https://pzwiki.wdka.nl/mw-mediadesign/images/9/91/Bs4-test-reddit1-3.png" alt="Bs4-test-reddit1-3" width="250%" height="250%"/> | |||
Latest revision as of 13:02, 5 October 2017
Prototype
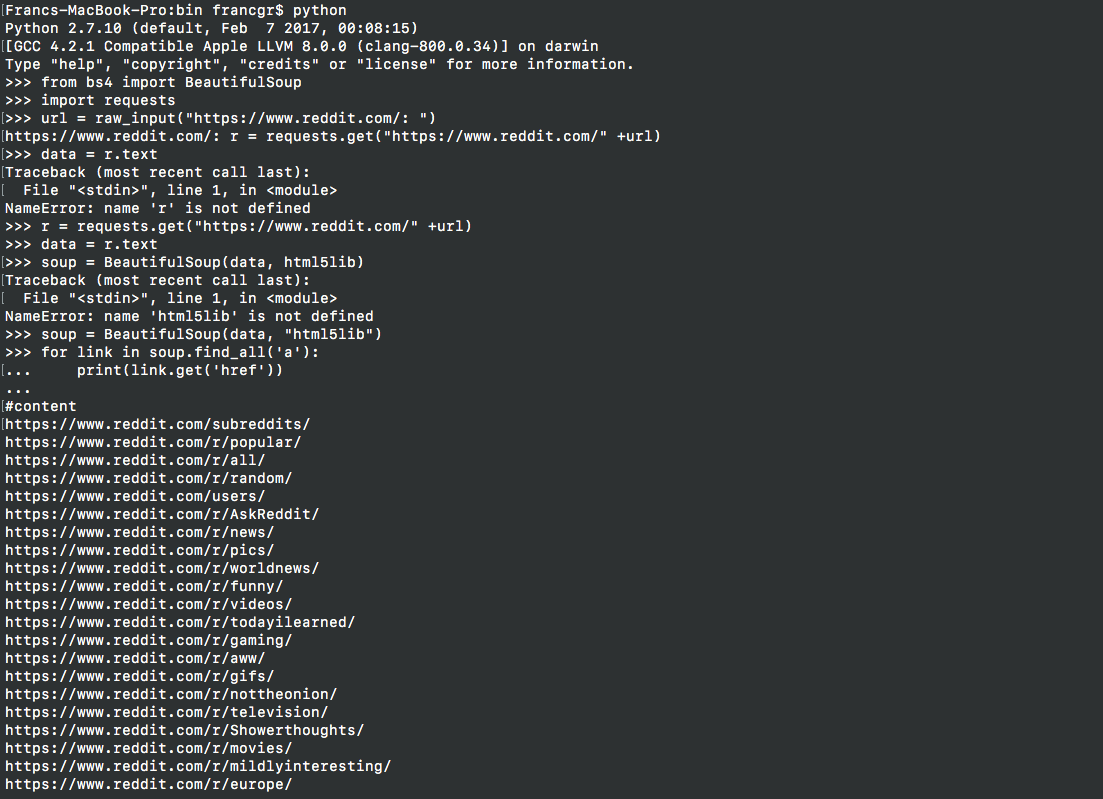
Extracting data (scrapping URL's / web links from content only)
from: https://www.reddit.com/
Run Python (I did it from virtual environment in my laptop)
then following these commands:
from bs4 import BeautifulSoup
import requests
url = raw_input("https://www.reddit.com/: ")
r = requests.get("https://www.reddit.com/" +url)
data = r.text
soup = BeautifulSoup(data)
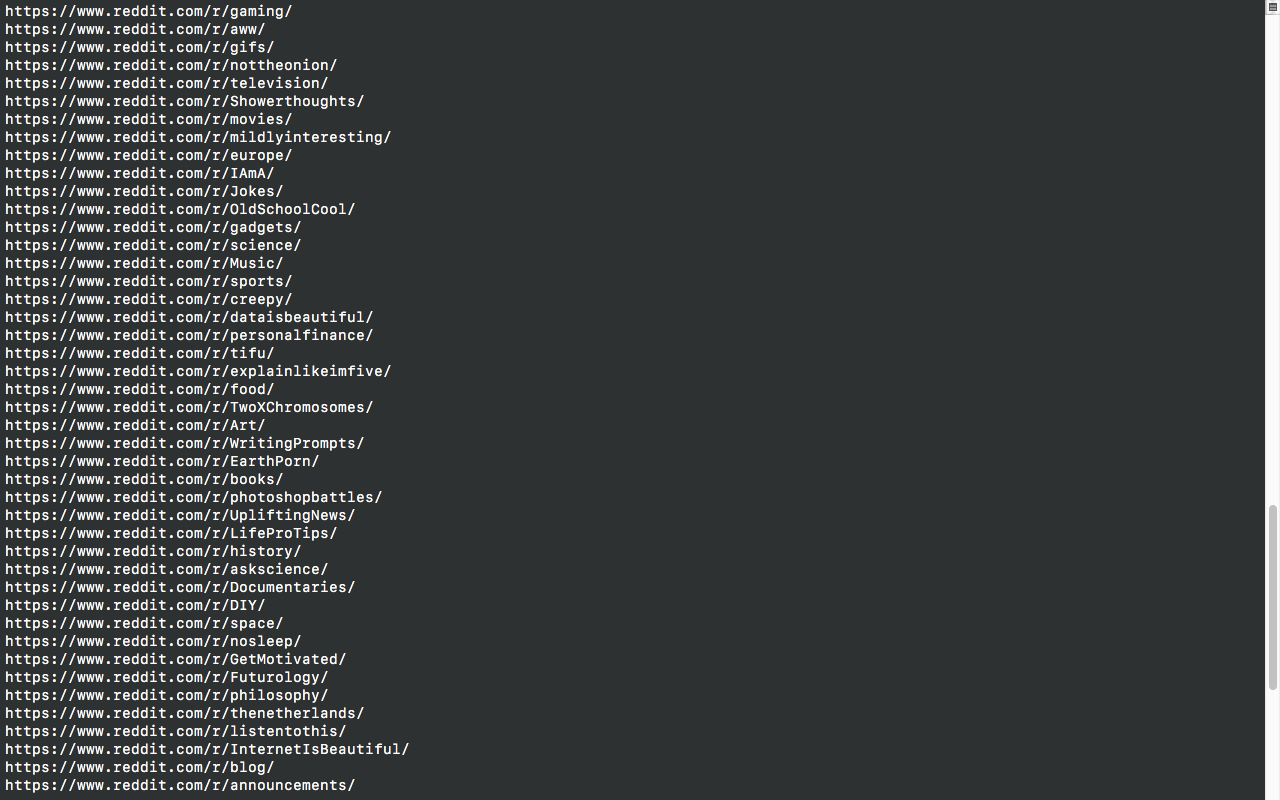
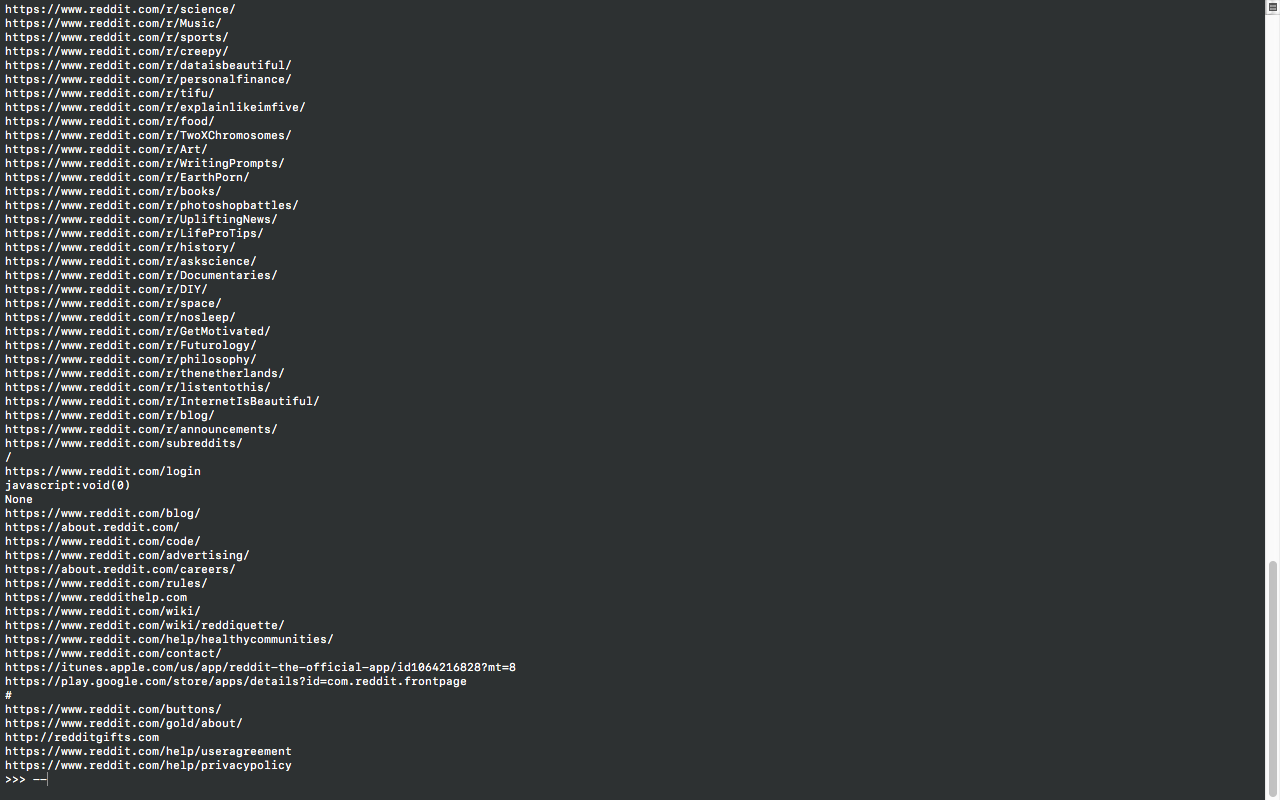
for link in soup.find_all('a'):
print(link.get('href'))
Bs4-test-reddit1-2.png