
User:Tash/grad prototyping: Difference between revisions
No edit summary |
|||
| (16 intermediate revisions by the same user not shown) | |||
| Line 244: | Line 244: | ||
</source> | </source> | ||
[[File:Django-factbook1.png| | [[File:Django-factbook1.png|470px|thumbnail|left|Map view using leaflet.js]][[File:Django-factbook2.png|470px|thumbnail|right|Detail view per country]] | ||
<div style="clear: both;"></div> | |||
== Machine learning workshop with Alex & Zalan 29.10.2018 == | |||
In this workshop we experimented with a simple machine learning algorithm, which used a binary classifier to 'read' and then 'label' images. | |||
We collected and established our own datasets to train and then test the algorithm. In our group, the instinct was to irritate or deceive the algorithm. | |||
We chose to train the algorithm to analyse imagery of birds vs planes. With a dataset of some 40 images the accuracy rate was quite low, maybe some 60%. | |||
The question of AI and machine learning is relevant to my research because of the way platforms use these approaches to censor content and/or users. | |||
<gallery class="left" widths=200px heights=140px> | |||
Predict4.jpg.predicted.png| machine sees: plane | |||
predict5.jpg.predicted.png| machine sees: bird | |||
Predict2.jpg.predicted.png| machine sees: bird | |||
Predict3.jpg.predicted.png| machine sees: plane | |||
</gallery> | |||
== Censoring your selfies for the afterlife == | |||
A strange phenomenon has developed on Indonesian social media: the rise of 'Account Deletion Services' aimed at women who have recently decided to wear the hijab, and thus need help erasing their past social media personas. Hashtags used include #akhwat ('Muslim sisterhood') #beranihijrah ('ready to reform / cut ties') #dosajariyah ('continuous sin / sins which follow you to the afterlife'). These accounts capitalise (literally) on the new ultra-conservative identity of Indonesian women. | |||
<br> | |||
They advertise using apocalyptic language, taking a moral stance on selfies, or indeed any images of women on social media, calling them sinful and un-Indonesian. Men, on the other hand, have no equivalent censorship on their image. This pressure on women to moderate their own image, is a kind of social censorship which I think contributes to the suppression of women's voice and place in public culture. It makes me wonder, as an Indonesian woman, where do I fit in today? | |||
<br> | |||
<gallery class="left" widths=210px heights=400px> | |||
Jasatutupakun1.jpg| Profile: 'Account closing service'. Bio: 'Admin is a Muslim sister / We can erase Facebook, Instagram, Twitter / Payment at the end.' | |||
Jasatutupakun2.jpg| 'Images and video of ourselves will haunt us in the afterlife' | |||
16.jpg| 'Not ready to cover your aurat? Don't worry, there's still space in hell' | |||
Jasa15.jpg| A happy customer | |||
Jasa14.jpg| 'My sister, don't upload your photo' | |||
Jasa12.jpg| 'A strong Muslimah is: Not one that can lift a gallon, but one that can take a good photo of herself and not upload it' | |||
Jasa3.jpg| 'Thank God, there are no photos of my wife on social media' | |||
Jasa5.jpg| Blurred women's faces on a popular Muslim account | |||
Jasa2.jpg| Blurred cartoon faces on the same account | |||
Jasa6.jpg| Comments under a photo of an Indonesian popstar, who is wearing revealing clothing. 'This is not the face or the look of an Indonesian' / 'Vulgar' / 'Where is your integrity as an Indonesian' | |||
Jasa1.jpg| 'A woman sometimes chooses not to voice everything that goes in her heart. This is for the greater good and to protect others' | |||
Jasa8.jpg| 'To guard your words is a way to be safe' | |||
</gallery> | |||
<br> | |||
'''Censoring my own Instagram profile''' | |||
<br> | |||
<br> | |||
[[File:InstaCensored 181104.png|990px|frameless|center]] | |||
== Hack: Uncensor me == | |||
For Indonesian women who change their mind. A service which offers prepackaged Instagram profiles, with stock images ready to be photoshopped with your face on it. | |||
[[File:Sketches 181104.jpg|900px|frameless|center]] | |||
== Hack: Secret Selfies == | |||
A secret profile for like-minded Hijabis to sinlessly share their selfies. | |||
[[File:Sketches 1811042.jpg|900px|frameless|center]] | |||
Latest revision as of 11:28, 6 November 2018
Prototyping 1 & 2

Possible topics to explore:
- anonymity
- creating safe, temporary, local networks (freedom of speech - freedom of connection!) http://rhizome.org/editorial/2018/sep/11/rest-in-peace-ethira-an-interview-with-amalia-ulman/
- censorship
- scraping, archiving
- documenting redactions
- steganography?
- meme culture
Learning to use Scrapy
Scrapy is an application framework for crawling web sites and extracting structured data which can be used for a wide range of useful applications, like data mining, information processing or historical archival. Even though Scrapy was originally designed for web scraping, it can also be used to extract data using APIs (such as Amazon Associates Web Services) or as a general purpose web crawler.
Documentation: https://docs.scrapy.org/en/latest/index.html
Scraping headlines from an Indonesian news site:

Using a spider to extract header elements (H5) from: http://www.thejakartapost.com/news/index
import scrapy
class TitlesSpider(scrapy.Spider):
name = "titles"
def start_requests(self):
urls = [
'http://www.thejakartapost.com/news/index',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for title in response.css('h5'):
yield {
'text': title.css('h5::text').extract()
}
Crawling and saving to a json file:
scrapy crawl titles -o titles.json
To explore
- NewsDiffs – as a way to expose the historiography of an article
- how about looking at comments? what can you scrape (and analyse) from social media?
- how far can you go without using an API?
- self-censorship: can you track the things people write but then retract?
- An Anthem to Open Borders
Scrape, rinse, repeat!
HTML5lib

Back to basics: using html5lib and elementtree to extract data from web sites. While Scrapy has built-in mechanisms which make it easier to programme spiders, this method feels more open to intervention. I can see every part of the code and manipulate it how I like.
import html5lib
from xml.etree import ElementTree as ET
from urllib.request import urlopen
with urlopen('https://www.dailymail.co.uk') as f:
t = html5lib.parse(f, namespaceHTMLElements=False)
#finding specific words in text content
for x in t.iter():
if x.text != None and 'trump' in x.text.lower() and x.tag != 'script':
print (x.text)
Selenium
Selenium is a framework which automates browsers.
It uses a webdriver to simulate sessions, allowing you to programme actions like following links, scrolling and waiting.
This means its more powerful and can handle more complex scraping.
Here's the first code that I put together, to scrape some Youtube comments:
# import libraries
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import os
import time
import datetime
today = datetime.date.today()
# get the url from the terminal
url = input("Enter a url to scrape (include https:// etc.): ")
# Tell Selenium to open a new Firefox session
# and specify the path to the driver
driver = webdriver.Firefox(executable_path=os.path.dirname(os.path.realpath(__file__)) + '/geckodriver')
# Implicit wait tells Selenium how long it should wait before it throws an exception
driver.implicitly_wait(10)
driver.get(url)
time.sleep(3)
# Find the title element on the page
title = driver.find_element_by_xpath('//h1')
print ('Scraping comments from:')
print(title.text)
# scroll to just under the video in order to load the comments
driver.execute_script("window.scrollTo(1, 300);")
time.sleep(3)
# scroll again in order to load more comments
driver.execute_script('window.scrollTo(1, 2000);')
time.sleep(3)
# scroll again in order to load more comments
driver.execute_script('window.scrollTo(1, 4000);')
time.sleep(3)
# Find the element on the page where the comments are stored
comment_div=driver.find_element_by_xpath('//*[@id="contents"]')
comments=comment_div.find_elements_by_xpath('//*[@id="content-text"]')
authors=comment_div.find_elements_by_xpath('//*[@id="author-text"]')
# Extract the contents and add them to the lists
# This will let you create a dictionary later, of authors and comments
authors_list = []
comments_list = []
for author in authors:
authors_list.append(author.text)
for comment in comments:
comments_list.append(comment.text)
dictionary = dict(zip(authors_list, comments_list))
# Print the keys and values of our dictionary to the terminal
# then add them to a print_list which we'll use to write everything to a text file later
print_list = []
for a, b in dictionary.items():
print ("Comment by:", str(a), "-"*10)
print (str(b)+"\n")
print_list.append("Comment by: "+str(a)+" -"+"-"*10)
print_list.append(str(b)+"\n")
# Open a txt file and put them there
# In case the file already exists, then just paste it at the bottom
print_list_strings = "\n".join(print_list)
text_file = open("results.txt", "a+")
text_file.write("Video: "+title.text+"\n")
text_file.write("Date:"+str(today)+"\n"+"\n")
text_file.write(print_list_strings+"\n")
text_file.close()
# close the browser
driver.close()
See workshop pad here: https://pad.xpub.nl/p/pyratechnic1
Programmatic scraping workshop with Joca 08.10.2018
Transcluded from Joca's page:
As part of the Py.rate.chnic sessions Tash and I organized a workshop about scraping. In Scrape, rinse, repeat we told about the use of scraping for our graduation research, showed some examples of artistic work enabled by scraping and let people scrape and remix online content themselves. We made example scripts to scrape content using Python with the libraries HTML5Lib, and Selenium.
I worked mostly on the HTML5Lib variant of the scraping scripts, building upon the script I made for the ACED workshop.
The workshop went well, and the results were interesting and diverse. Creating the format, and preparing the workshop was quite a challenge: the Py.rate.chnic sessions are new and the programming skills in the group of participants are really varied. I am positive about the workshop, and some aspects went smoother than expected. For example: getting the example scripts to work on all computers. The assignment we gave to the participants was really open. Making that more specific, for example by scraping 1 website, could make the outcomes of more value to our research. On the other hand, because we are both quite at the beginning of our research, it made sense to keep the goal of the workshop general: introduce people to scraping, and the use of it for making new work.
Newspaper scraping exercise 08.10.2018
As part of the scraping workshop I led with Joca, we analysed the interface, content and structures of printed newspapers.
We looked at pages from the New York Times, the Daily Mail and the New European, and used our knowledge of element trees to deconstruct the paper's layout.
I found it to be a playful way to explore the visual language of this kind of media. Some questions that came up: how important is aesthetics in the design of trust / authority?
What could news media learn from the language of vernacular media, and vice versa?

Learning Django
Django is a database-driven python framework for building web applications. It works with Jinja and SQL, and has a lot of similarites to the Flask framework which we used for XPPL. However, where Flask has decoupled its dependencies (allowing you more control, to pick and choose what other frameworks to work with), Django provides an all-inclusive experience: you get a built-in admin panel, database interface and ORM.
Out in the real world, Django seems to be used as the main framework powering many applications, whereas Flask is often used just for API's.
Some of the well-known projects powered by Django include Pinterest, Disqus, Eventbrite, Instagram and Bitbucket.
Pinterest now uses Flask for its API. Other projects using Flask include Twilio, Netflix, Uber, and LinkedIn.
Django directory structure
Again, some similarities to Flask here. But it's great that Django has built-in 'startproject' and 'startapp' commands, that will auto-generate your main files for you.
django-admin startproject mysite
Which creates:
└── mysite
├── manage.py
└── mysite
├── **init**.py
├── settings.py
├── urls.py
└── wsgi.py
Creating a new app, which for this sketch we'll call 'factbook', since we'll be using a sample database from the CIA World factbook.
python manage.py startapp factbook
Which creates:
└── mysite
└── factbook
├── _**init**_.py
├── admin.py
├── apps.py
├── migrations
│ └── _init_.py
├── models.py
├── tests.py
└── views.py


Machine learning workshop with Alex & Zalan 29.10.2018
In this workshop we experimented with a simple machine learning algorithm, which used a binary classifier to 'read' and then 'label' images. We collected and established our own datasets to train and then test the algorithm. In our group, the instinct was to irritate or deceive the algorithm. We chose to train the algorithm to analyse imagery of birds vs planes. With a dataset of some 40 images the accuracy rate was quite low, maybe some 60%. The question of AI and machine learning is relevant to my research because of the way platforms use these approaches to censor content and/or users.

machine sees: plane

machine sees: bird

machine sees: bird

machine sees: plane




Censoring your selfies for the afterlife
A strange phenomenon has developed on Indonesian social media: the rise of 'Account Deletion Services' aimed at women who have recently decided to wear the hijab, and thus need help erasing their past social media personas. Hashtags used include #akhwat ('Muslim sisterhood') #beranihijrah ('ready to reform / cut ties') #dosajariyah ('continuous sin / sins which follow you to the afterlife'). These accounts capitalise (literally) on the new ultra-conservative identity of Indonesian women.
They advertise using apocalyptic language, taking a moral stance on selfies, or indeed any images of women on social media, calling them sinful and un-Indonesian. Men, on the other hand, have no equivalent censorship on their image. This pressure on women to moderate their own image, is a kind of social censorship which I think contributes to the suppression of women's voice and place in public culture. It makes me wonder, as an Indonesian woman, where do I fit in today?
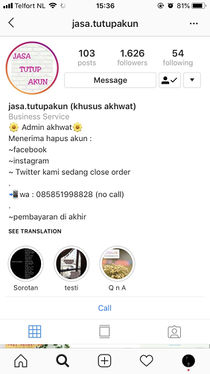
Profile: 'Account closing service'. Bio: 'Admin is a Muslim sister / We can erase Facebook, Instagram, Twitter / Payment at the end.'
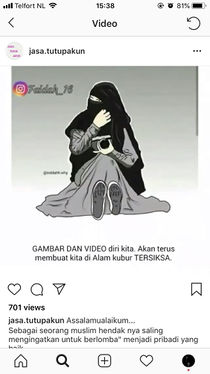
'Images and video of ourselves will haunt us in the afterlife'
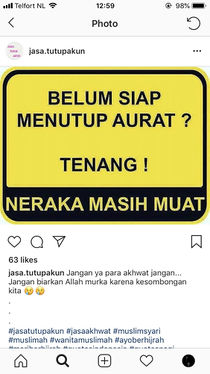
'Not ready to cover your aurat? Don't worry, there's still space in hell'
A happy customer
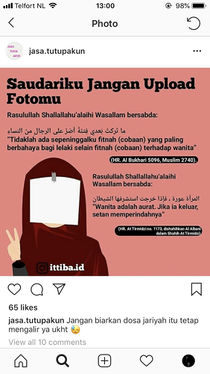
'My sister, don't upload your photo'

'A strong Muslimah is: Not one that can lift a gallon, but one that can take a good photo of herself and not upload it'
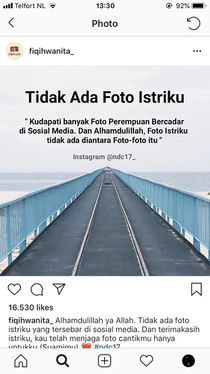
'Thank God, there are no photos of my wife on social media'

Blurred women's faces on a popular Muslim account

Blurred cartoon faces on the same account
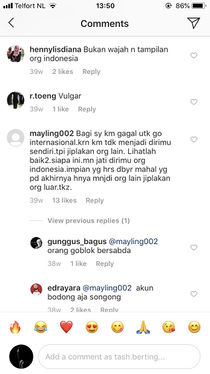
Comments under a photo of an Indonesian popstar, who is wearing revealing clothing. 'This is not the face or the look of an Indonesian' / 'Vulgar' / 'Where is your integrity as an Indonesian'
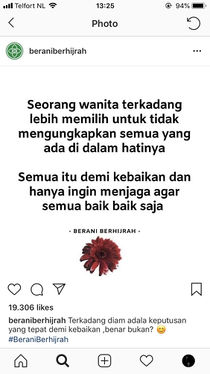
'A woman sometimes chooses not to voice everything that goes in her heart. This is for the greater good and to protect others'
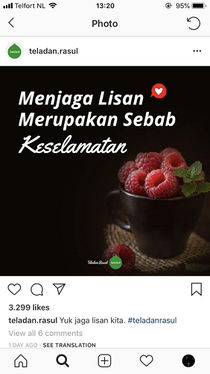
'To guard your words is a way to be safe'












Censoring my own Instagram profile

Hack: Uncensor me
For Indonesian women who change their mind. A service which offers prepackaged Instagram profiles, with stock images ready to be photoshopped with your face on it.

Hack: Secret Selfies
A secret profile for like-minded Hijabis to sinlessly share their selfies.
