User:Francg/expub/thesis/draft2: Difference between revisions
No edit summary |
No edit summary |
||
| (16 intermediate revisions by the same user not shown) | |||
| Line 9: | Line 9: | ||
</center> | </center> | ||
We live in an era where information technology is unceasingly creating large amounts of data, causing | We live in an era where information technology is unceasingly creating large amounts of data, consequently causing information overload, which sometimes exceed our capacity as users for processing it and understanding it. This large amounts of data can be communicated, reproduced, transformed and spread from all over the world, becoming available almost instantaneously. On one hand, even though this expansion and accumulation of data may be producing an abundance of knowledge, it is on the other hand also affecting our daily performance by exposing us to a lot of change in a very short time. That is to say, every user is taking part in this never-ending process of generating knowledge in which digital journalism, RSS feeds, social medias or other instant messaging tools, are significantly stressing up this phenomena. We are currently living in a mass production, mass distribution, mass consumption, mass education and mass entertainment society that is simultaneously functioning as a weapon for mass misinformation, ranging from useful to inaccurate or unverified content. | ||
Having this information anxiety established and standardised in our lives, it can be confusing to analyse critically an | Having this information anxiety established and standardised in our lives, it can be sometimes quite difficult and confusing to be able to analyse critically current issues. It would be useful to get an idea of the amount of information produced and how fast these are modified, changed by online journalism in relation to the same topic and how fast these news are being changed. | ||
In order to find out, I | In order to find out, I will extract and archive all the data generated by selected news feed in relation to the current sociopolitical conflict between Spain and Catalonia, which is causing information overload in the medias. To do this, I will make a wide selection of local and international RSS news feeds related to this topic. One of the issues here will be to filter the news that aren't related to it. Can this be achieved in an automated way or there has to necessarily be labor involved? | ||
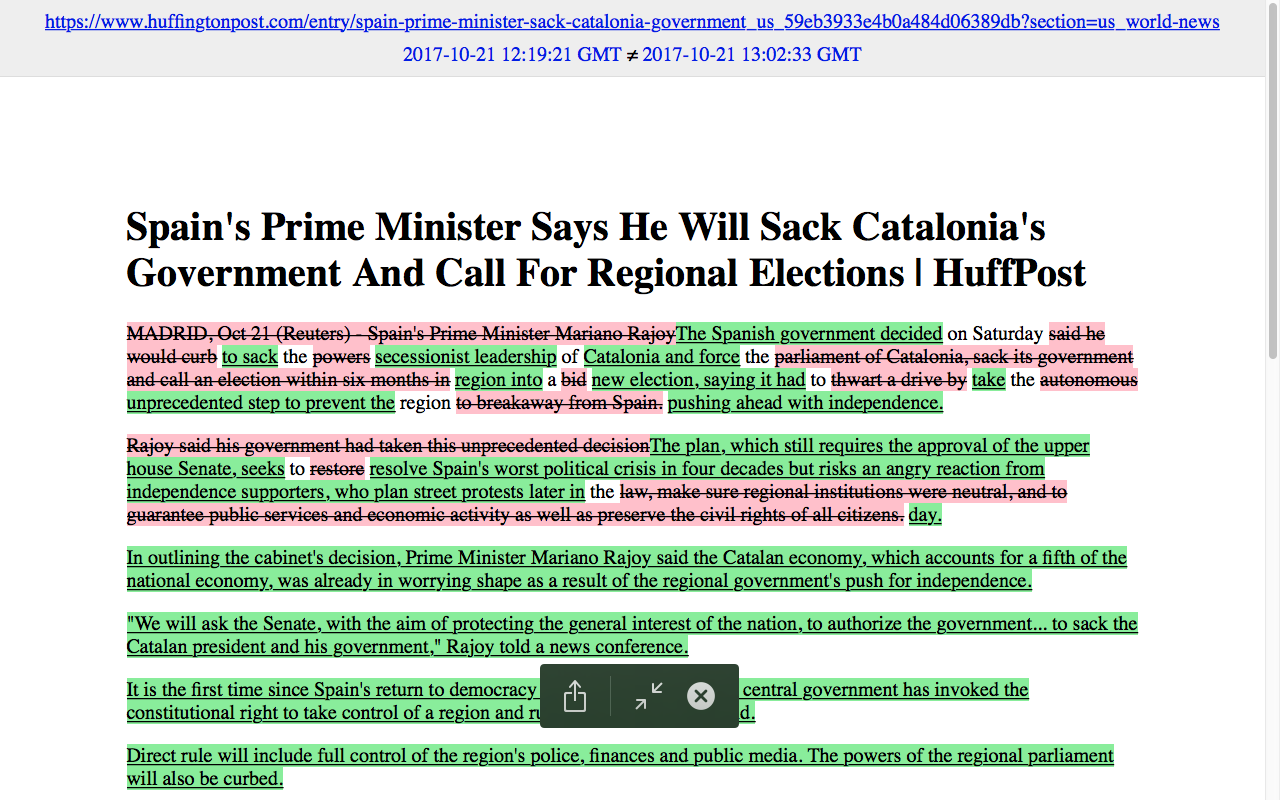
Combining diffengine and python programming tools, RSS news feeds will be monitored every 5 minutes (unless configured differently); if information is changed, a snapshot of these modifications will be created (highlighting deleted text in red and new written text in green). This creates 2 jpg and 1 html files, which includes other metadata like time of publication, geolocation and a link to the original source. Using web-scrapers such as Beautiful Soup or tools such as Feedme or Twarc might be useful to scrape specific websites or groups in social medias like Twitter, Instagram or Facebook that don’t use RSS technology. Web scraping can also be used to create a specific word count from a text file, which can be interesting for comparing syntactical strategies from different sources. | |||
This data will automatically be updated and hosted in a database (mongoDB or SQL like) from the local network of a raspberry pi, in order to reinforce the methods used by the group of hackers against the network surveillance during the 1-October in Barcelona's anti-constitutional referendum, but also to be critical with the assumption of "freedom of speech" when state power is imposed. They made possible a registered universal census system, despite its non juridic recognition and the violence employed by the state. Additionally, allowing access to this data base trough onion browsers like Tor it would preserve user's anonymity and help address ethical concerns when documenting particular sources. This data base will not only be an eyewitness of the actual demographic issue which will allow to compare news, verify them and to understand better what's happening, but it will also be a democratic tool/publication in defense of freedom of information, allowing users to access raw materials/content and additional collaboration features from invited figures (articles, essays, comments, interviews, etc.). | |||
Eventually these results can be further used to conduct a wider research to promote awareness on the effects of information overload and how we experience this information. This may also help drawing attention on how sometimes online journalism might look for quick information rather than verified one. This data can also be used to produce a series of books compiling some of these “epic” news changes. | |||
<br>'''-> Check out the hackpackt site to see these examples:''' https://pzwiki.wdka.nl/mediadesign/User:Francg/expub/thesis/hackpackt | |||
<br> | |||
https://pzwiki.wdka.nl/mw-mediadesign/images/a/a8/Dff-huffington.png | |||
</div> | </div> | ||
Latest revision as of 12:49, 30 October 2017
Draft Project Proposal
19.10.17
We live in an era where information technology is unceasingly creating large amounts of data, consequently causing information overload, which sometimes exceed our capacity as users for processing it and understanding it. This large amounts of data can be communicated, reproduced, transformed and spread from all over the world, becoming available almost instantaneously. On one hand, even though this expansion and accumulation of data may be producing an abundance of knowledge, it is on the other hand also affecting our daily performance by exposing us to a lot of change in a very short time. That is to say, every user is taking part in this never-ending process of generating knowledge in which digital journalism, RSS feeds, social medias or other instant messaging tools, are significantly stressing up this phenomena. We are currently living in a mass production, mass distribution, mass consumption, mass education and mass entertainment society that is simultaneously functioning as a weapon for mass misinformation, ranging from useful to inaccurate or unverified content.
Having this information anxiety established and standardised in our lives, it can be sometimes quite difficult and confusing to be able to analyse critically current issues. It would be useful to get an idea of the amount of information produced and how fast these are modified, changed by online journalism in relation to the same topic and how fast these news are being changed.
In order to find out, I will extract and archive all the data generated by selected news feed in relation to the current sociopolitical conflict between Spain and Catalonia, which is causing information overload in the medias. To do this, I will make a wide selection of local and international RSS news feeds related to this topic. One of the issues here will be to filter the news that aren't related to it. Can this be achieved in an automated way or there has to necessarily be labor involved?
Combining diffengine and python programming tools, RSS news feeds will be monitored every 5 minutes (unless configured differently); if information is changed, a snapshot of these modifications will be created (highlighting deleted text in red and new written text in green). This creates 2 jpg and 1 html files, which includes other metadata like time of publication, geolocation and a link to the original source. Using web-scrapers such as Beautiful Soup or tools such as Feedme or Twarc might be useful to scrape specific websites or groups in social medias like Twitter, Instagram or Facebook that don’t use RSS technology. Web scraping can also be used to create a specific word count from a text file, which can be interesting for comparing syntactical strategies from different sources.
This data will automatically be updated and hosted in a database (mongoDB or SQL like) from the local network of a raspberry pi, in order to reinforce the methods used by the group of hackers against the network surveillance during the 1-October in Barcelona's anti-constitutional referendum, but also to be critical with the assumption of "freedom of speech" when state power is imposed. They made possible a registered universal census system, despite its non juridic recognition and the violence employed by the state. Additionally, allowing access to this data base trough onion browsers like Tor it would preserve user's anonymity and help address ethical concerns when documenting particular sources. This data base will not only be an eyewitness of the actual demographic issue which will allow to compare news, verify them and to understand better what's happening, but it will also be a democratic tool/publication in defense of freedom of information, allowing users to access raw materials/content and additional collaboration features from invited figures (articles, essays, comments, interviews, etc.).
Eventually these results can be further used to conduct a wider research to promote awareness on the effects of information overload and how we experience this information. This may also help drawing attention on how sometimes online journalism might look for quick information rather than verified one. This data can also be used to produce a series of books compiling some of these “epic” news changes.
-> Check out the hackpackt site to see these examples: https://pzwiki.wdka.nl/mediadesign/User:Francg/expub/thesis/hackpackt