User:Francg/expub/thesis/prototype: Difference between revisions
(Created page with " <center> '''Extracting URL's from any website''' Now when we know what BS4 is and we have installed it on our machine, let's see what we can do with it. from bs4 import B...") |
No edit summary |
||
| (7 intermediate revisions by the same user not shown) | |||
| Line 1: | Line 1: | ||
<div style="font-size:100%; letter-spacing: 0.05em; line-height: 1.6em; margin-left: 80px; margin-right: 140px;"> | |||
<center> | <center> | ||
<br> | |||
'''Prototype''' | |||
Extracting data (scrapping URL's / web links from content only) | |||
<br>from: https://www.reddit.com/ | |||
<br> | |||
<br> | |||
</center> | |||
from | Run Python (I did it from virtual environment in my laptop) | ||
<br>then following these commands: | |||
import requests | <br>from bs4 import BeautifulSoup | ||
<br>import requests | |||
<br>url = raw_input("https://www.reddit.com/: ") | |||
<br>r = requests.get("https://www.reddit.com/" +url) | |||
<br>data = r.text | |||
<br>soup = BeautifulSoup(data) | |||
<br>for link in soup.find_all('a'): | |||
<br> print(link.get('href')) | |||
Bs4-test-reddit1-2.png | |||
<img src="https://pzwiki.wdka.nl/mw-mediadesign/images/9/98/Bs4-test-reddit1.png" alt="Bs4-test-reddit1" width="250%" height="250%"/> | |||
<img src="https://pzwiki.wdka.nl/mw-mediadesign/images/5/56/Bs4-test-reddit1-2.png" alt="Bs4-test-reddit1-2" width="250%" height="250%"/> | |||
<img src="https://pzwiki.wdka.nl/mw-mediadesign/images/9/91/Bs4-test-reddit1-3.png" alt="Bs4-test-reddit1-3" width="250%" height="250%"/> | |||
Latest revision as of 13:02, 5 October 2017
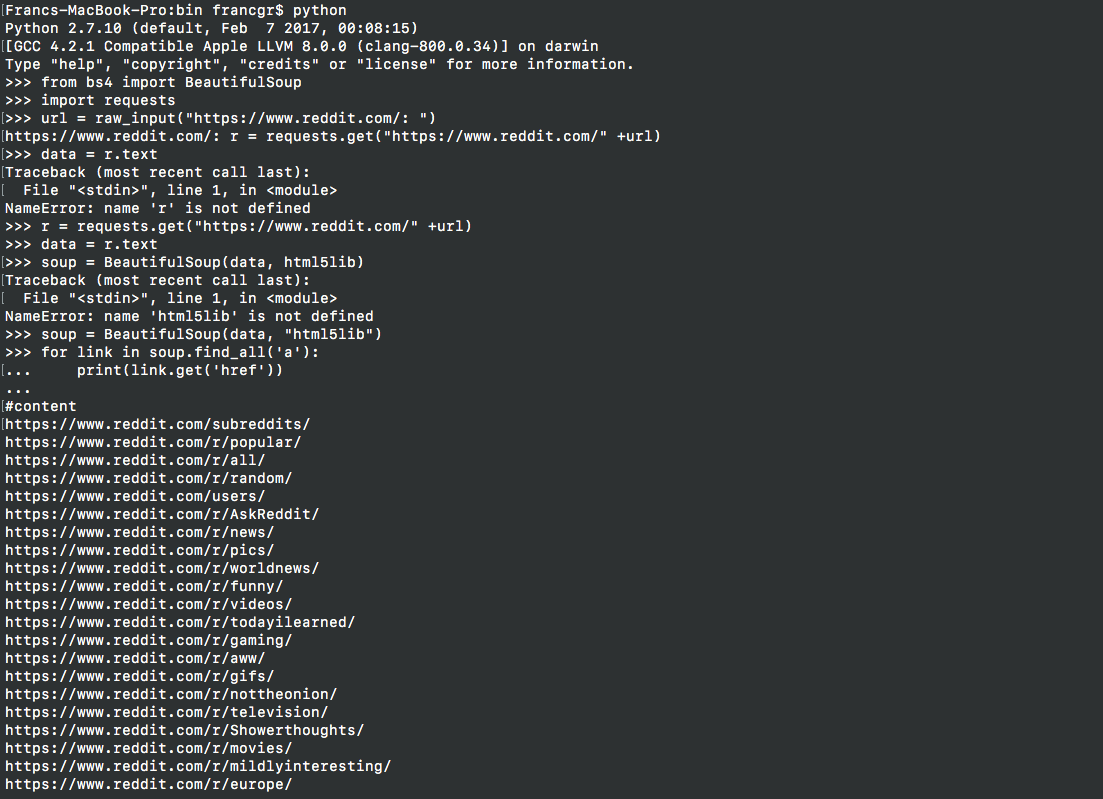
Prototype
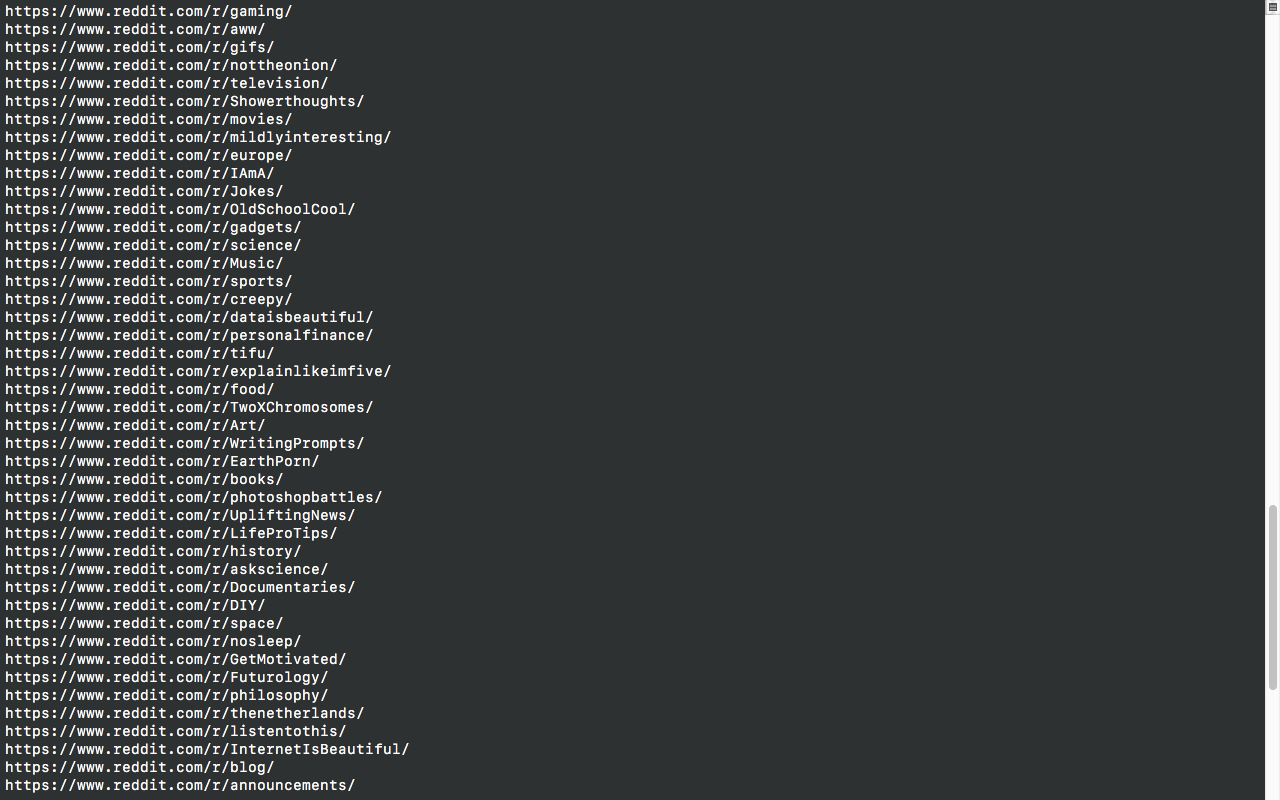
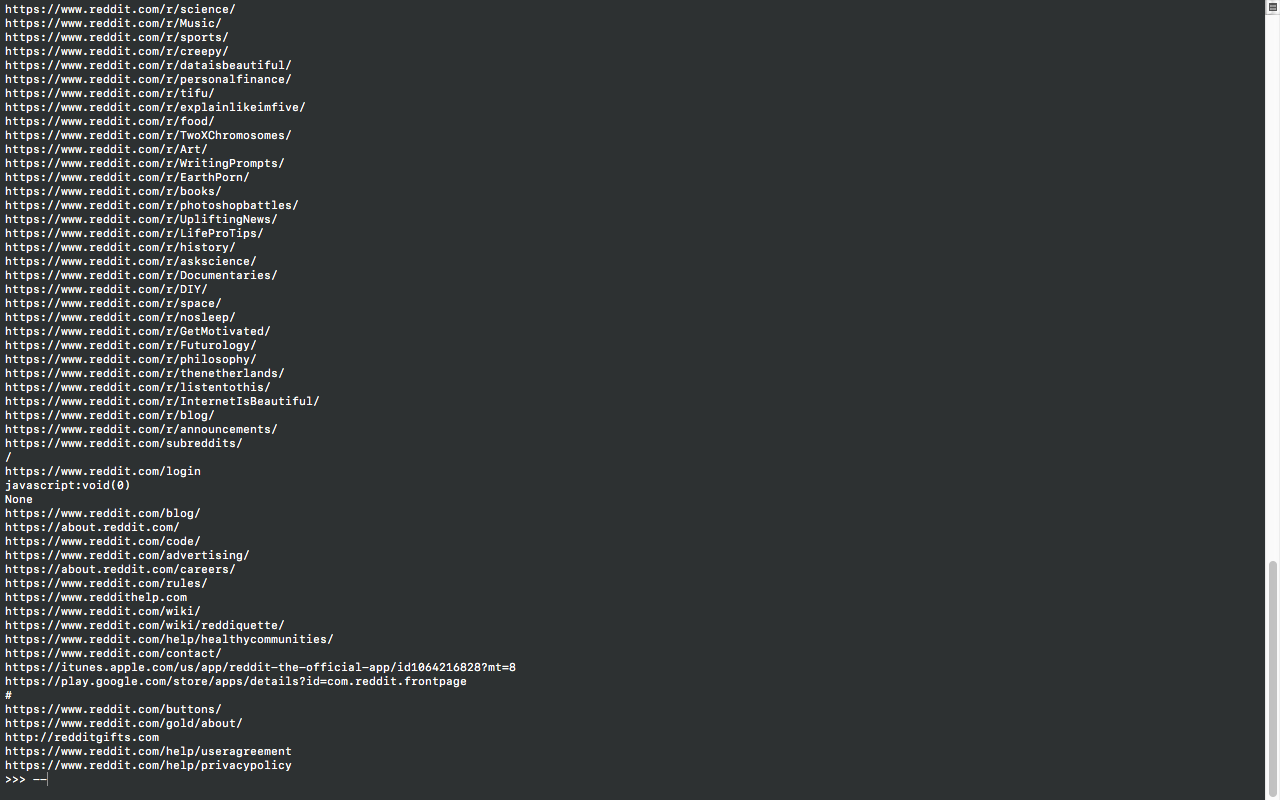
Extracting data (scrapping URL's / web links from content only)
from: https://www.reddit.com/
Run Python (I did it from virtual environment in my laptop)
then following these commands:
from bs4 import BeautifulSoup
import requests
url = raw_input("https://www.reddit.com/: ")
r = requests.get("https://www.reddit.com/" +url)
data = r.text
soup = BeautifulSoup(data)
for link in soup.find_all('a'):
print(link.get('href'))
Bs4-test-reddit1-2.png