
User:FLEM/Poems translations
.input
i recently received a new poetry book from the same author of a book that I've been carrying with me for a long time
one day, while reading my favourite poem, Fiesta, I started to play around with the two translations offered by both books
i did like that word, i did not like the structure of the sentence in the other translation, i wanted a different word for the end of that line
at the end i created a new translation based on the two originals and i started to question myself on this topic
how does a translator choose words?
why do they choose .a instead of .b? .c instead of .a?
not all translations are perfect so then, why not mix them up?
.what
A function that:
1. takes into account 2 similar texts (example: 2 different translations of a poems)
2. finds the common words and uses them as the fixed text for the new piece of text
3. puts the results together into a new piece, randomly choosing the different options
4. html output that highlights the different random choices of the translations

example of two compared poems

example of joined text with translation options


.the poem
.fiesta
The glasses were empty So the glasses were empty
The bottle was shattered and the bottle broken
The bed was wide open And the bed was wide open
The door was tight shuttered and the door closed
Each shard was a star And all of the glass stars
Of bliss and of beauty of happiness and beauty
That flashed on the floor were sparkling in the dust
All dusty and dirty of the poorly dusted room.
And I was dead drunk And I was dead drunk
Lit up wildly ablaze And I was a bonfire
You were drunk and alive And you were alive, drunk,
In a naked embrace! all naked in my arms.
.what does vernacular processed translations mean?
//vernacular// means made by humans for humans, vernacular is the material I am gathering through the Annotation Compass°, a place where everyone can have access to, where everyone can give their contribution, regardless of their background or knowledge etc.
//processed// means that the content gathered through humans' actions is transformed by the machine to create something new.
what we are gathering, what we are processing, everything is //language//. in the case of the impossible process, we are using translations, in particular translations of poems.
translation of poems is not the easiest translation to be done; it requires a lot of knowledge of both languages involved, but what makes vernacular translations unique is it gathers translation from people that know and approach languages in very different ways. The result can give a deeper overview of the poem!
.vernacular maps as a starting point
starting from the data received from the tool of the vernacular maps
comparing results and find out common words / differences but the content wasn't the right one to do this made a function for common words
from collections import Counter Counters_found = Counter(labels4_split) most_occur = Counters_found.most_common(4) print(most_occur)
started to think about my interest in poems' translations and wanted to look for the common words in those texts.. a new idea was coming into my head
.poem translations function
This tool is thought to compare two different translation of the same poem and obtain a result that randomly chooses and mix up the two translation into a new text.
.a choose poems
.b select two translations
.c find out sentences and words that are different
.d import random from choice (from the differences of the texts' translations)
.e highlight the word that's different/ the random choice
//.f when you slide on it you can see the different options//
.vernacular poem translations
by collecting translations made by people from different languages and comparing them
.a choose a poem in english
.b provide different language translations
.c ask people to use the translation in their own language and to translate it to english
//.d compare the original translation with the new vernacular ones//
// why not going back to the vernacular maps and try out the labelling tool on this content? ANSWER FOUND (continue reading..)
.vernacular translations maps
."seeing what different translators have done with the same poem immediately eliminates easy assumptions that beginning translators often make: that there is a single way, a most correct way, or a best way to translate a poem." ."We might begin by asking where, on a continuum ranging from the most “literal” to the most “free,” a particular translation lies. Where, on another continuum between most loyal to form and most free of it, does a translation of a formal poem lie? What is gained by attempting to replicate meter and/or rhyme, and what is lost? What about levels of diction? More generally, what is the stylistic “register” of a translation, ranging from formal to colloquial, or is there a mixture of styles?"°
why not going back to vernacular maps with this? not even need my filter, the filter serves just to analyse material in a specific way. why not create vernacular maps from these vernacular translations? ask people to write on the image of the text their personal translation. what is the right way to translate a poem? then work on the content gathered and create new maps out of the texts
instructions: translate the following text to english in the way you feel, word by word, using negative space writing on the text off the text following the lines or not? //
update 02.12.21: for the vernacular tool, to gather data, i have to start from a singular file, shared between the users. therefore is not possible to choose a text to be translated to english. instead, i'm going to choose a text in english for everyone and then people will annotate on it.
maybe, afterwords, i could try to find translations of the text in other languages and compare them, but it is not really necessary. //
! this is a tool for internationals? no, everyone can translate in the language they want and the original text chosen can be in different languages
instructions: translate the following text to your mother language//a different language in the way you feel, word by word, using negative space writing on the text, off the text, following the lines or not? //
.the impossible process of grasping the other side
the impossible process of grasping the other side is a project by Emma Prato, as part of the Special Issue 16 //Learning How to Walk While Catwalking// carried out by Piet Zwart Institute (XPUB) students on the topic of Vernacular Language Processing.
the impossible process basically wants to play around with the structure of poetry translations and mix together different versions of the same text.
translating a poem into another language is an impossible process - so what if we gather translations from different people? from different languages? and what if then we mix them up? what if we change them? what if we play with words? it probably won't solve the impossible process but for sure is an interesting experiment.
//multiple translations can give us a much better sense of the poem than a single translation can, so that even if we can’t read the poem in the original language, we can come closer to that experience° // the impossible process is made of two sections: one (THE CROWD) is to gather //vernacular// information and the other (THE MASHUP) is to process texts, which can be both taken from the vernacular content or from already existing translations. The poetry archive (work in progress) will showcase the results.
.the impossible process – THE MASHUP // USE THE MASHUP() FUNCTION
the impossible process – THE MASHUP tries to approach the impossible process of translation by the use of a Python function that:
1. takes into account two different translations of a poem
2. finds the common words and uses them as the fixed text for the new piece of text
3. puts the results together into a new piece, randomly choosing the differences in the two texts
The resulting text will show how many different ways there are to translate a text, a line, a concept, a single word.
the impossible process is a funny way to highlight the thousand facets of a translation and create // never-ending // new texts randomly choosing the differences.
.the impossible process – THE CROWD // CONTRIBUTE TO THE IMPOSSIBLE PROCESS
the impossible process – THE CROWD consists into three annotation methods, in order to gather different material from users, then to process the texts and create new vernacular content.
The results will be part of the Archive. If you want to contribute to the Archive of vernacular translations (or experimental texts), choose a method, access the image, insert your translation and wait for your text to be used.
go on reading at .different approaches to vernacular poem translations
.the impossible process – ARCHIVE OF VERNACULAR POEMS
the purpose of this archive is divalent: the first is to gather vernacular translations from users around the world, and to fill this archive with translations that don't exist yet -- the second is to create always new random versions of already existing translations, or of vernacular translations, to play around with language and words.
.different approaches to vernacular poem translations
.one to one translation
start from a poem in x language (see experiment below) in order to gather data from users and be able to use the results with mashup() function
--> can the function be used for more than 2 texts?
.one to one translation experiment
- duty
find a poem in italian to upload on the labelling tool and ask people to translate it to english in specific lines so that then the results can be used to create new translated texts with the mashup() function.
- poem chosen
I ragazzi che si amano
I ragazzi che si amano si baciano in piedi
Contro le porte della notte
Ed i passanti che passano li indicano col dito
Ma i ragazzi che si amano
Non ci sono per nessuno
Ed è la loro ombra soltanto
Che trema nella notte
Suscitando la rabbia dei passanti
La loro rabbia il loro disprezzo le loro risa la loro invidia
I ragazzi che si amano non ci sono per nessuno
Sono altrove molto più lontano della notte
Molto più in alto del giorno
Nell’abbagliante luce del loro primo amore
- usage instructions
Welcome to poem translation!
I would like you to translate this poem to english. You can use a translator to obtain the translation of single words, but i hope you will do your best to make a thoughtful choice on the word you will choose. Every word has its own power!
this collection of translations will be part of the material I will use to experiment with my mashup() function, which can be used only with texts with the same number of lines. Therefore, I kindly ask you to create the spaces next to the text, in order, and one space per line. This is so that the content extracted will be ready to be processed.
.a Go to https://hub.xpub.nl/soupboat/generic-labels/annotate/one_to_one_translation.jpg/ .b Click and drag to create the space(s) where you want to insert your translation (line by line, in order, one space per line) .c Click insert or click on the x if it's not as you want
Thank you for your participation! Get back on our website soon to see how your contribution has been used.
.many to one translation
start from the same text translated from the original language to different languages. Users can choose the language they prefer to start from and then insert the translation to english (//common language) through the labelling tool. The results can then be used for the mashup() function.
.many to one translation experiment
- duty
find a poem translated in different languages to upload on the labelling tool and ask people to translate it to english in specific lines so that then the results can be used to create new translated texts with the mashup() function.
- poem chosen
- usage instructions
FIRST: CHOOSE THE LANGUAGE TO START FROM (list of links? options? mmm)
Welcome to poem translation!
I would like you to translate this poem to a english. You can use a translator to help you with the translation of single words, but i hope you will do your best to make a thoughtful choice on the word you will choose. Every word has its own power!
this collection of translations will be part of the material I will use to experiment with my mashup() function, which can be used only with texts with the same number of lines. Therefore, I kindly ask you to create the spaces next to the text, in order, and one space per line. This is so that the content extracted will be ready to be processed.
.a Go to .b Click and drag to create the space(s) where you want to insert your translation (line by line, in order, one space per line) .c Click insert or click on the x if it's not as you want
Thank you for your participation! Get back on our website soon to see how your contribution has been used.
result: https://pad.xpub.nl/p/poem_transl
.free fun translation
start from a common language, let people interact as they want and then create vernacular maps put of the results?
.free fun translation experiment
- duty
find a poem in english to upload on the labelling tool and let people annotate and interact with the poem as they want.
- poem chosen
This is actually not a well-known poem so it's possible that finding translations wouldn't even be so easy. But, doesn't this make the tool even more interesting?
First Party At Ken Kesey's With Hell's Angels by Allen Ginsberg
Cool black night thru redwoods
cars parked outside in shade
behind the gate, stars dim above
the ravine, a fire burning by the side
porch and a few tired souls hunched over
in black leather jackets. In the huge
wooden house, a yellow chandelier
at 3 A.M. the blast of loudspeakers
hi-fi Rolling Stones Ray Charles Beatles
Jumping Joe Jackson and twenty youths
dancing to the vibration thru the floor,
a little weed in the bathroom, girls in scarlet
tights, one muscular smooth skinned man
sweating dancing for hours, beer cans
bent littering the yard, a hanged man
sculpture dangling from a high creek branch,
children sleeping softly in their bedroom bunks.
And 4 police cars parked outside the painted
gate, red lights revolving in the leaves.
December 1965
- usage instructions
there is NOT a single way, a most correct way, or a best way to translate a poem.
following this quote, I would like you to translate this poem to the language you prefer/feel more comfortable with/your mother tongue. You can use a translator to obtain the translation of single words, but i hope you will do
your best to make a thoughtful choice on the word you will choose. Every word has its own power!
interact with this text as you prefer and translate it in the way you feel, word by word, using negative space, writing on the text, off the text, following the lines or not?
.a Go to https: https://hub.xpub.nl/soupboat/generic-labels/annotate/free_fun_translation.jpg/ .b Click and drag to create the space(s) where you want to insert your translation .c Click insert or click on the x if it's not as you want
.production process
.from my notebook
.from my notebook 18.11.21
book translations
.a choose poems
.b take different translations
.c select sentences and words that are different
.d import random from choice (from the text's translation
.e highlight the word that's different
.f when you slide on it you can see the different options EXTRAJAVA
.from my notebook 26.11.21
text1 = " the glasses were broken "
text2 = " the glass is broken "
starting text = " the _____ ____ broken"
random choice between glasses were // glass is
random chosen poem translation
.a print differences
.b print equals
.c organise random choice scheme?
fixed_terms + choice(differences) // remove differences leaving a space reference --> replace?
! in a line, it should choose one version
could it be possible to highlight differences later? now use the whole sentence now
.from my notebook 29.11.21
.a go through the text --> find difference
e i bicchieri eran vuoti
ed i bicchieri erano vuoti
.b reposition with random choice
// tokenize words
should this be random choice with no meaning or actually putting the text back in order to show the real translations?
.from my notebook 30.11.21
gathering information from people reading poems out loud and producing transcriptions with the use of an automatic translator // compare them between different languages? with vernacular poems? with originals?
.not from my notebook 01.12.21
.seeing what different translators have done with the same poem immediately eliminates easy assumptions that beginning translators often make: that there is a single way, a most correct way, or a best way to translate a poem."
.We might begin by asking where, on a continuum ranging from the most “literal” to the most “free,” a particular translation lies. Where, on another continuum between most loyal to form and most free of it, does a translation of a formal poem lie? What is gained by attempting to replicate meter and/or rhyme, and what is lost? What about levels of diction? More generally, what is the stylistic “register” of a translation, ranging from formal to colloquial, or is there a mixture of styles?°
--> why not going back to vernacular maps with this? not even need the filter, the filter exists just to analyse material in a specific way. why not create vernacular maps from these vernacular translations? ask people to write on
the image of the text their personal translation. what is the right way to translate a poem? then work on the content gathered and create new maps out of the texts
instructions: translate the following text to english in the way you feel, word by word, using negative space writing on the text of the text following the lines or not? //
.not from my notebook 02.12.21
The point of this project is that it's not necessary to start with poems translations // this is a really specific way of using this function and the one i will use to explain the use of this tool// it is a tool that permits user to compare two similar texts, highlighting differences.
.from my jupiter lab
.differ function
Poem_translations_diff Poem_translation_diff is a function that compares two different translations of the same text and gives the differences between the two texts
how to use: to use this function it is necessary to have two texts with the same number of lines (as it goes through the two texts and compares them line by line). Probably it will be ok to use both .txt files and strings but not figured it out yet --
input: 2 texts that are similar but not the exact copy of each other --
output: // still not clear yet //
1. import difflib (and html to display result) 2. define texts + split in lines (now, then it will probably be words?)
import difflib from IPython.display import HTML, display
3. html style to show the result visually
style= """<style>
span.del
{
background-color:#b0c4de;
}
span.add
{
background-color:#b064de;
}
</style>"""
4. initiate the differ object
5. for loop, by using code (+/-) resulted by differ
6. adding style to (+/-) results to see them visually
Each line of a Differ delta begins with a two-letter code:
'- ' line unique to sequence 1 '+ ' line unique to sequence 2 ' ' line common to both sequences '? ' line not present in either input sequence
def difftexthtml(text1,text2):
d = difflib.Differ()
# calculate the difference between the two texts
diff = d.compare(text1, text2)
src=
for result in diff:
code, word = result.split(' ', 1)
word = word.strip()
#src = src + word + ' '
if code == '-' :
src = src + f'{word}'
elif code == '+' :
src = src + f'{word}'
else:
src = src + word + ' '
return src
6. for loop, by using code (-) resulted by differ to identify "deleted words" // they are just sentences of text1
- initiate the Differ object
def diff_deleted_words(text1,text2):
d = difflib.Differ()
# calculate the difference between the two texts
diff = d.compare(text1, text2)
del_words= []
for result in diff:
code, word = result.split(' ', 1)
word = word.strip()
#src = src + word + ' '
if code == '-' :
del_words.append(word)
return del_words
.find differences and equal words in texts
"Find differences and equal words in texts" is a function that compare two different translations of the same text and gives the differences and equal words between the two texts
how to use: this function (at the moment) works with strings
input: 2 texts that are similar but not the exact copy of each other --
output: // still not clear yet // should be a new piece of text that puts the results together, randomly choosing from the differences
1. import difflib + sequencematcher+ split texts
2. import collections and orderset definition -- so that set() is not random but OrderSet() //in order
- ORDERSET DEFINITION
import collections
class OrderedSet(collections.Set):
def __init__(self, iterable=()):
self.d = collections.OrderedDict.fromkeys(iterable)
def __len__(self):
return len(self.d)
def __contains__(self, element):
return element in self.d
def __iter__(self):
return iter(self.d)
3. Get differences in the two lists of words
#Get the different words in two lists of words
def Diff(text1, text2): return list(OrderedSet(text1) - OrderedSet(text2)) + list(OrderedSet(text2) - OrderedSet(text1)) text22="ed i bicchieri erano vuoti e la bottiglia infranta ed il letto spalancato e l'uscio era sprangato" text2 = text22.split() text11="E i bicchieri eran vuoti la bottiglia in pezzi Il letto spalancato e la porta sbarrata" text1 = text11.split() print(Diff(text1, text2)) #print the difference differences = (Diff(text1,text2))
4. Get fixed_terms (equal words) in the two lists of words
# to get the words that are not the different ones def fixed(text1,text2,differences): return list(OrderedSet(text1)-OrderedSet(differences)) + list(OrderedSet(text2)-OrderedSet(differences)) print(fixed(text1,text2,differences)) fixed_terms1 = (fixed(text1,text2,differences))
5. for loop of random choice to choose from the differences and equals // it doesn't work with texts/lines with a different structure than "fixed+difference+difference+fixed"
- i need to find out how to print the text using the structure of the original text
from random import choice
result=()
for words in fixed_terms1:
for words in differences:
print(fixed_terms1[0] + ' ' + choice(differences) + ' ' + choice(differences) + ' ' + fixed_terms1[1])
.poem_translations_zip
zip is a function for loop with zip function to go through the texts and print out html style
how to use: to use this function it is necessary to have two texts with the same number of lines (as it goes throught the two texts and compares them line by line)
input: 2 texts that are similar but not the exact copy of each other --
output: a new text that showcase the differences
1. import difflib (and html to display result) 2. define texts + split in lines (now, then it will probably be words?)¶
3. html style to show the result visually
style= """<style>
span.del
{
background-color:#b0c4de;
}
span.add
{
background-color:#b064de;
}
</style>"""
4. zip line by line the whole text
for line_A, line_B in zip(text1, text2): words_A = line_A.split() words_B = line_B.split() src = difftexthtml(words_A, words_B) delwords = diff_deleted_words(words_A, words_B) #print(line_A) #print(line_B) #print(delwords) display(HTML(style + src))
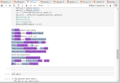
result

.mashup()
1.define texts (at the moment 2 texts)
2.import difflib and from random import choice
3.define fixed_words with Differ and compare functions and loop through the fixed_words of first line of text1 and text2
text1 = text1.splitlines() #split texts in lines
text2 = text2.splitlines()
fixed_words= [] #define empty list for fixed_words (words that are the same in both texts) // a list of lists of words
for line_A, line_B in zip(text1, text2): #start the first loop reading line by line from both texts at the same time (=zip)
words_A = line_A.split() #split lines in lists of words
words_B = line_B.split()
d = difflib.Differ() #Differ compare sequences of lines of text, and produce human-readable differences ('+' in text1), ('-' in text2), ( fixed_Words)
diff = d.compare(words_A, words_B) #compare the difference between the two lists of words
linelist = [] #define empty list
for result in diff: #second loop that goes through all the lines and then the words of both texts simultaneously
code, word = result.split(' ', 1) #split result of diff in code [('+'), ('-') or ()] and the resulting word (is it the same or is it just in one of the two texts?)
word = word.strip() #to be sure it doesn't have any weird things /n at the ends of the lines
if code == : #if the code is ' ' (nothing) it means that the word can be found in both texts
linelist.append(word) #if this happens, put the corresponding words in the linelist
fixed_words.append(linelist) #afterwards, add linelist to fixed_words (linelist is inside the loop so all the words in every line are put in there, but fixed_words is outside so that just the words are added just once)
4.find the index of the fixed_word in this line of text1 and text2, then roll the dices and print choice
length = len(text1) #define lenght of text1
for linenumber in range(length): #for the number of the lines in the lenght of the text
cut_left1 = 0 #the beginning of both texts is position n°0 (on the left side of the lines)
cut_left2 = 0
words_1 = text1[linenumber].split() #words_1 is split in words keeping the position in the lines
words_2 = text2[linenumber].split()
if len(fixed_words[linenumber]) > 0: #if the index on the fixed words in the line is more than 0 (it's not the first one)
for fixed_word in fixed_words[linenumber]: #for all the fixed_words that are in the fixed_words list always following the linenumbers
cut_right1 = words_1.index(fixed_word) #finding the first fixed_word from the left (beginning / position 0) to the right(end of sentence / last word in the line)
cut_right2 = words_2.index(fixed_word) #in both texts
slice_1 = words_1[cut_left1 : cut_right1] #create slice_1
slice_2 = words_2[cut_left2 : cut_right2]
print(choice([slice_1, slice_2]))
cut_left1 = cut_right1 #now invert, when it's gone through all the words till finding the last fixed word
cut_left2 = cut_right2
slice_1 = words_1[cut_left1 :] #from the last fixed_word found to the right
slice_2 = words_2[cut_left2 :]
print(choice([slice_1, slice_2])) #choose
else:
slice_1 = words_1[cut_left1 :] #here is doing it outside of the loop ( it gets the last word of the line if it's not a
slice_2 = words_2[cut_left2 :]
print(choice([slice_1, slice_2])) #choose
print('--------')
5.do it again
.methodology
.a new text with highlighted differences
.b both texts alongside
.c new text from random choice
.content
.a fixed poem translation // analysis and comparison of two different translations
.b vernacular translations (made by people) // print out all the different translations in all languages
.physical output
--> possibility to extract the resulting file (pdf, txt file, word?)
// framed prints of the processes showcased step by step, also with mistakes --> printed(results) in the Jupiter Lab
// a collective book of different translations of the same poem? printed out as vernacular maps!
! do a session with people trying out the tool and print the results out
.the impossible process in the special issue 16 //FINAL OUTPUTS
.the impossible process website
visit the page to enjoy the full experience! CLICKHERE

Homepage design
Homepage design





.png)
.png)
.png)
.png)
.png)
.png)
.png)
.the impossible process prints
the process of creating THE MASHUP() function has gone through many mistakes, try-outs and unexpected results. Here you can see a selection of all of this mess, from my Jupiter Lab.
print1 shows the difftexthtml() function. This function has been used to showcase the differences between the two texts directly in the Jupiter Lab: sadly, the function wasn’t working to put together the texts and create a new one, but it is useful to understand the logic.
Light blue is text1, purple is text2, the non-coloured parts are the fixed words. The next step was to understand how to recreate the text after defining the words!
print2 shows every line of both texts, in []: I was trying to split the texts into single words, defining the different ones and the fixed ones, to put them back together afterwards. Unfortunately, I realised the function could not work following this methodology and I had to save the structure of the text to be able to put it back together after.
print3 is how the final mashup() function looks like in the Jupiter Lab: every time I reload the function, a new result will come up. And this is how the function actually works on the website. Go and try it out!

print1

print2

print3



.the impossible process toolkit
.content and instructions
inside this paper bag you will find 2 different translations of the same poem:
a. an original text by Derek Walcott
b. a vernacular translation, made by one of XPUB students by using the Annotation Compass.
in addition, you will find:
c. a clean sheet of paper where to recreate the poem
d. on the backside of this sheet, instructions on what to do to experience at best the impossible process
After finishing with the paper work and understanding the mechanism, access the mashup() webpage, where you will be able to try out the function and the magic power of the API, starting to learn how to walk (while catwalking) with us.

the impossible project toolkit

the impossible project introduction

the impossible project how to



{kind=link}
{kind=link}
.possibilities
.why this is an enriching and fascinating tool
confronting texts in education to understand differences?
to understand the job of a translator?
create vernacular and popular translations of texts that have never been translated before
to enrich the experience of reading a translated text?
.More specifically, multiple translations can give us a much better sense of the poem than a single translation can, so that even if we can’t read the poem in the original language, we can come closer to that experience. °
.on the topic
https://pamelaklein.wordpress.com/2012/07/12/translation-generator-poetry/
https://lithub.com/what-we-can-learn-from-multiple-translations-of-the-same-poem/