
Category:Prototypology
Microphonology
piezoelectric element

ceramic piece + metal piece. wires are solded ? on them
Also called a “contact microphone”.
Single coil

A coil of copper wires
Magnetic inputs are translated
We can listen to electric radiation.
ghost busters
There is a coil in the speaker, that creates membrane.
We listen to electricity when we put the coil near e. Devices
The membrane has electric coil inside, that start to pick up (?)
The
coil unit measure = Henry (H)
Why can’t we hear the things that the coil microphone picks up?
The coil is a spiral shaped thing… which creates a magnetic field. (made from which material?)
In an e-guitar, the string is moving in a certain frequency, and while doing that, it interrupt the magnetic field of the coil. And therefore, it creates an electric current.
This electric current needs to be amplified to be heard.
Henry unit: https://www.britannica.com/science/henry-unit-of-inductance
Electric current is not air vibrating.. instead it exists of magnetic waves.
The more coil, the more sensitive it is for magnetic waves.
It does not respond to air moving, but to magnetic waves.
You can speak into it though, as your voice will make the XXX move.
There are different terms used to refer to translating something into sound: “sonification” is a term being used to turn things into sound, and there is also the term “audibility” which acknowledges that things are already make sound, you need to translate it into something that we can hear.
in the field of electroacoustics
Coil picks up the vibration and starts to resonate with it.
Coils are used for amplifying, they are used pick up vibrations from the membrane.
EXAMPLE
When we put a coil mic on the power cable…:
- there is electricity in the power cable of 220 V, it vibrates on 50 hz (this is ⚡AC, alternating current, which means that it moves from +’s to -’s) (⚡DC direct current)
- we hear the AC, because the switching between +’s and -’s is influencing the current of the coil
- the mixer amplifies the signal
- the sound it send to the computer, where it is digitized: inside the computer there is an Analog to Digital CXXX (ADC)
bits
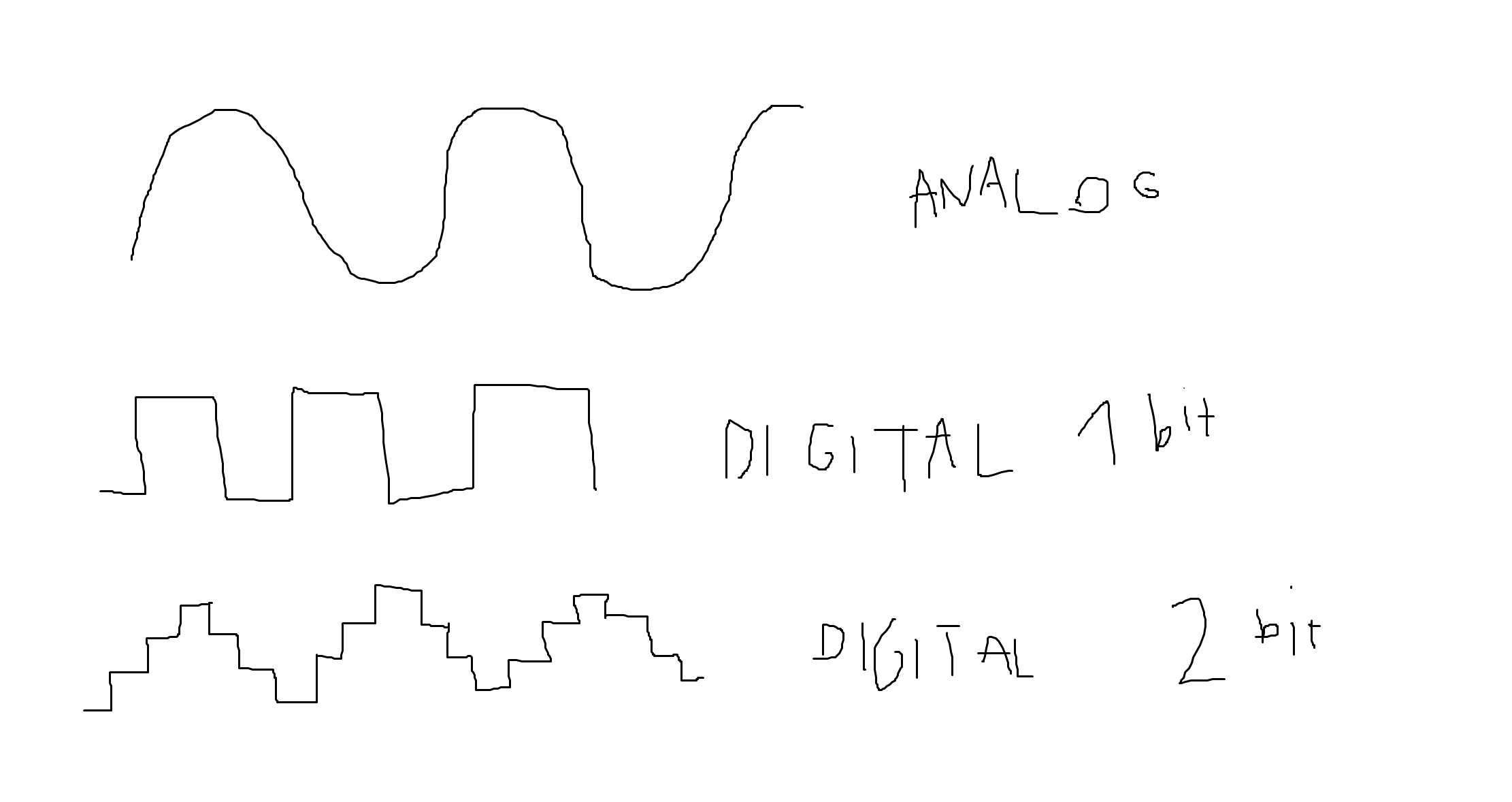
analog signal = wave (round formed wave)
ADC –> analog dicgital converter
digital signal = 0 1 (square formed wave) (bit is the resolution) (this is an one-bit signal)
1 bit = 2 steps
2 bit = 4 steps
4 bit = 16 steps
You express bits in khz.
For example: 48khz or 22 khz.
The more bits, the “better” the quality.
But this is relative, as some people really like 8-bit sounds for example.
hertz Hz
1 hz = one wave/second
15 hz = 15 hertz/second
frequency !
100 hz = 100 waves per second
this is a frequency of 100 hz
100 hz sounds lower
1000 hz sounds higher
the higher the frequency, the higher the tone
If you get older, you slowly cannot hear the higher part of the frequency spectrum anymore.
Everything over 10000 is harder for older generations to hear.
And generally you can hear from 100 hz/sec.
High frequencies are used as ringtones by younger people, as the teachers cannot hear them anymore.
High frequencies are also used as mosquito devices in the city (of Rotterdam) as a control device for public space.
dynamic microphones
The dynamic microphone (also known as the moving-coil microphone) works via electromagnetic induction. […] Dynamic microphones use the same dynamic principle as in a loudspeaker, only reversed. A small movable induction coil, positioned in the magnetic field of a permanent magnet, is attached to the diaphragm. When sound enters through the windscreen of the microphone, the sound wave moves the diaphragm. When the diaphragm vibrates, the coil moves in the magnetic field, producing a varying current in the coil through electromagnetic induction. A single dynamic membrane does not respond linearly to all audio frequencies. For this reason, some microphones utilize multiple membranes for the different parts of the audio spectrum and then combine the resulting signals. (Wikipedia)
SM58 microphone
Looks like a speaker, and it is actually a speaker.
With a microphone you get the current, with a speaker you give current.
If you speak, the membrane starts to vibrate, this creates a current in the coil, the coil then gets pre-amplified in the mixer and the audio output.
“the current in the coil”
This microphone is similar to the coil e-guitar microphone, as it is also based on coil.
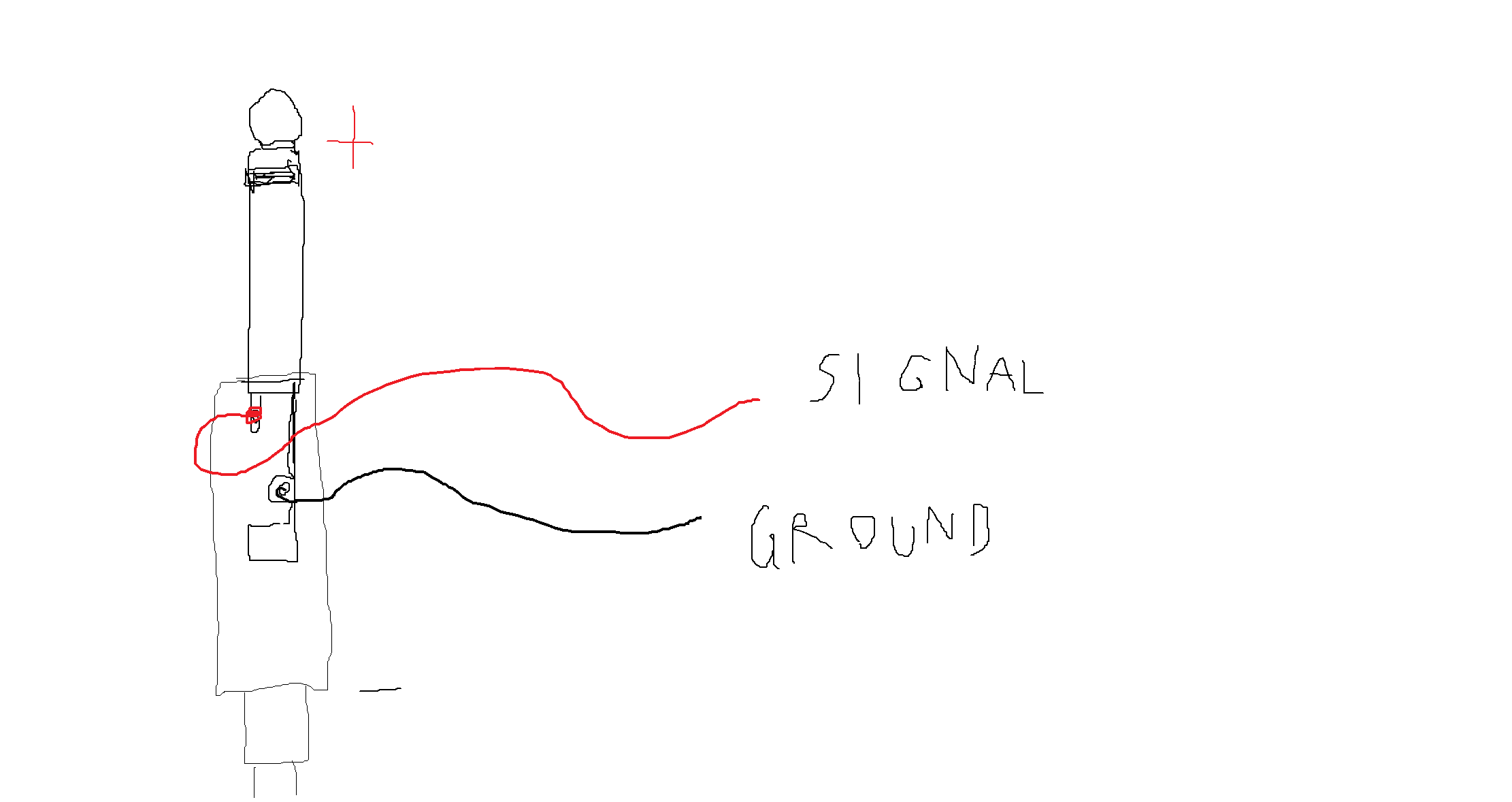
Jack connector
You can open it.
The “tip” picks up the signal.
The larger pipe is the “ground”.
When you solder the piezzo mic, you connect the black cable (the ground) to the ground of the jack connector.
What medium do you use to communicate?
Medium of air
Medium of electricity
microphone: vibrations into signal
Electrical signals are always about difference: you always need to measure the signal and the ground. You need the ground to understand what/where the signal is. It’s a point of reference.
Soldering
You can solder a piezoelectric or coil microphone.
You need: jack connector + microphone of choice + cable.
A cable is a set of wires with plastic around it. Two cables cannot touch each other. The plastic also protects the cable from picking up electromagnetic waves, to make sure you pick up a “poor” signal. This is called “interference”, which is the unwanted picked up signals, which people like theater producers strongly fear while working.
Step 1: strip your cable
Strip the (black) plastic from the end of your cable. It does not matter how much you take off, but 2 cm is useful.
They have a great tool downstairs in the interaction station, called a stripper, to take the plastic of the wires.
Once you opened it, you will find a blue and red cable.
Step 2: place the cable in the jack connector
There are two square parts on the end of the jack connector. In between, you can put the whole cable.
Take a tool (“knijptang” in Dutch) and push it together. This is just to hold it.
Step 3: isolate the red and blue cables
Isolate the red and the blue cable, this means: take a bit from the plastic from the ends of these cables.
Pick a small cutting tool, and take 5mm of the plastic from the ends of the red and blue cable. You can also do this with your finger nails, but make sure that the two cables (the red and the blue) do not touch each other!
Now you see the small wires.
Step 4: solder the cable to the jack connector
Take the solder material.
It melts at 320 Celsius degrees.
Just take a little of it, like 30 centimeters.
Take a third hand.
This is a device with little teeth that you can use to put your wires in.
Take the soldering iron.
You don’t have to use it like a pen, you just need to heat up the things you want to solder.
Don’t touch the tip of the soldering iron! It’s super hot.
The idea is that you heat up the wire, and once you place the soldering material to the wire, it will solder itself.
This is “tinning”: heating a piece of metal (the connection point), then touch it to the solder, and then it connects the two together.
Connect the red cable to the upper small hole (the one closest to the tip of the jack connector).
Connect the blue cable to the lower one (the one closest to the square holding piece at the bottom of the jack connector).
So, let’s solder!
First: Heat up the cable for 3 cm (tinning).
Then: Put the solder material to the cable.
Step 5: solder the cable to the microphone
Isolate the other side of the red and blue cable.
Cut 1 piece of** blue shrinking tube**, something like 2cm (the wider one).
Put it on the main cable.
Cut 2 pieces of white shrinking tube, 5mm each (the more narrow one).
Put one of the red and one on the blue cable.
Place the main (black) cable into the third hand.
Seperate the blue and the red cables, to make sure that they do not touch each other.
Heat the red and the blue cable and put some solder on it.
Heat one of legs of the microphone and put some solder on it.
Do it closely to the microphone itself, the legs are a bit too long.
Repeat this step for the other leg of the microphone.
So now, you have solder material on both cabled (red and blue) and on both legs of the microphone.
Because there is material already on both the cable and the leg of the mic, you only need to heat the solder material up a bit and it will connect the cable to the mic.
Now we are ready to solder the cable and mic together. Put the mic in the third hand, to make it easier to solder.
It does not matter which cable is connected to which microphone leg.
Heat the material on one of the legs a bit and connect one cable.
Repeat this for the other leg and cable.
Now put the white shrinking tube around the place where you connected the red cable with the mic.
Heat the shrinking tube by putting the soldering iron onto it, so it will shrink around the cable and protect the connection.
Repeat this for the blue cable.
Now first test your microphon!
Put it into the mixer.
To test a coil microphone, you can place it onto a phone, where it should pick up some electromagnetic waves.
To test a piezo microphone, you can place it on the table and knock, or place it to your neck and speak, to pick up vibration.
u
If it works, you can continue. If not, you can look at your soldering connections again to make sure they are connected well.
Now put the blue bigger piece of shrinking tube onto the part that you just soldered.
Heat it up with the soldering iron to shrink it.
Recordology + Audio-Editorology
We rented two ZOOM audio recorders from the WdKA rental for this week.
You can find the WdKA rental on the ground floor on the Wijnhaven side, and also see what they have here: https://rental.mywdka.nl/.
Where is the rental? Upon entry of Wijnhaven, keep left. Up the stone steps, through the corridor.
More information about the rental can be found here: https://static.mywdka.nl/facilities/rental-shop/wdka-rental/
One basic rule with recording: the level should not go above 0db, and a lit a bit under 0db; so you can see the levels going up and down.
echo echo echo echo echo
You can record in mono and stereo.
Spectogram
Maps time (horizontal) and frequencies (vertical); you see that the voices are happening on different frequencies at the same time. Looks like an abstract painting/tapestry.
Some composers draw images with spectograms, as a way to make sound. We will come back to this in the coming weeks.
An example: Venetian Shares - Look (from songs about my cats 2001).
https://www.youtube.com/watch?v=BHup81lEjqo
Another musician that did this was Aphex Twin: https://www.youtube.com/watch?v=M9xMuPWAZW8
Around 5khz the signal becomes almost white.
http://lesportraitsaudacieux.blogspot.com/p/on-en-parle.html
Equalizer
You can work with an equalizer.
to clean out the noise in a recording
equalization:
inside the equalizer you can see the different frequencies of the audio piece. you can use the equalization to filter frequencies that you don't want. or to isolate and improve the ones that you want.
Audacity
Audio editing
Simple audio editing software. It’s free software, you can install it on your computer, follow the instructions here: https://www.audacityteam.org/download/.
manuals for audacity https://archive.flossmanuals.net/audacity/
you can make glitched images with it
and look at the spectrogram of audio
When you record in Audacity, your recording is too loud when the blue waves touch the top and bottom.
Question: It is possible to add channels, voices etc, like the layers in photoshop? yes.
Question: How to blend multiple voices into one piece of sound? file > export> .wav format
wav: high res file format, uncompressed.
mp3: low res file format, suitable for the web as it is less big in terms of Mb’s; compressed file format
ogg: another low res file format, also suitable for the web; compressed file too
Small anecdote: Spotify only streams music in low res file formats, to not make it too heavy.
Save your audio to file
- export > wave .wav
- encoding: signed 16-bit PCM (this one is fine)
- #** the more bits, the more quality you have
- #** the pixels of the audio file
- save
Questions
Why can decibels be negative?
Why are the waves of the analog signals so organic? And the digital ones are square?
A 1 bit digital system only can save data in 2 states: 1 and 0.
A 16 bit system can save data in = 2^16 states = 65536 states in total.
How to record (maybe this part should go to recordology? for later):
- avoid to get to close to the microphone, otherwise you get the socalled pop effect. (you can see that the green line that signals the sound volume turns red (clipping)
- check your setting in your os: sometimes you get a square-ish wave in audacity, that means that your input level in your settings / system preferences is not balanced
- when recording in audacity, look at the horizontal scale on the top: the sound input should be close to 0 decibel but never actually reach 0 decibel (you will be in the orange-red-zone if you are too close) [the vertical scale of each sound wave (-1.0 to +1.0) shows the frequency (=amplitude per second?), which is not the same scale as the decibel]???? nope decibel db is the volume so to say and the frequency is in hertz Hz but the -1.0 +1.0 scale is neither decibel nor hertz right? i guess not, right thx I’m not sure but i though 1 and -1 has to do with the fact that waves are seen and drawn in graphics only between 1 and -1 in mathematics aaaaah so you see the shape of the wave but it’s frequency and the amplitude is mapped onto this range of -1 and 1.
- watch out when you add up multiple tracks in audacity (the same track multiplied twice and played simultaneously will duplicate the amplitude of the sound (volume)) why the microphone understands the power supply frequency??
there’s a mixer that converts AC into DC and it gets the 50hz freq
if the mixer lacks of a filter called (???) it might happen that you hear the electricity that gives power to it
to filter noise in the rec:
select a profile for the noise (literally select the part of the audio where there is a moment of silence and you can only hear the noice you wanna filter) then goto >filter>noise reduction> get noise profile then select the entire piece of audio and again >filter>noise reduction>ok
effects with audacity
loops
select a piece of audio, effects>repeat> …choose the n of repetitions you want
stretch
select a paulstretch from the effects menù
reverb
reverse
recording studio notes

XPUB PC
- password: opisop
- software: Audacity, Rack (synthesizer software)
Mixer
- XPUB/PC: the input coming from the computer
- the black L/R cables at top right: output to the speakers
- red knobs: the connection back to the computer (for recording with a microphone)
- orange nobs: the connection to the osciloscope
- black knobs: controlling the left and right
- MIC1: the left fader is to control the volume to the speakers
About recording with the microphone: currently you can only record mono. We are missing some cables at the moment. Maybe we can do some changes next week and allow for mono recording. Joak is ordering cables, Kamo can bring some that can be used in the meantime.
About the effects: the effects on the mixer make weird noises
Audio interface
The red box is Kamo's and can be used to mix multiple audio inputs at the same time.
Transcodology
transcoding = convert a digital file
for example from .wav to .mp3
.wav = very good quality, big file
.mp3 = less quality, smaller file
similar to converting images from .tif to .jpg
Using FFmpeg
Notebook with examples: https://hub.xpub.nl/soupboat/SI18/documentation/ffmpeg/
Also available on paper ;).
Before we start with this part
Upload your recording to the soupboat: shared/html/SI18/00/recordings/
Which you can see from the “outside” here: https://hub.xpub.nl/soupboat/SI18/00/recordings/
When doing ffprobe
Mp3’s can be compressed in different ways.
cpr
bpr
If the bitrate is very high, the filesize is more, and the quality will be better.
We can look in the upcoming weeks to look at very low bitrate, the lower the glitchier bit rates, to see what it does.
It is a way to learn about the Mp3 compression algorithm.
The visual sister of Mp3 is JPEG. Which is also a compressed image format.
What is the recommended bit rate for Mp3s?
128kb/s is normal, good quality. standard settings usually make tiny files but good quality
Does changing the frequency have an impact on the sound?
Depends. It can make it slower or faster.
How to change the bit rate?
add -b:a to the ffmpeg command
compression –> see notebook on the soupboat “transcodology”
Publishology
The issue website for SI18: https://issue.xpub.nl/18/
Upload the release to the soupboat in shared/html/SI18/00/: https://hub.xpub.nl/soupboat/SI18/00/
Update the issue webpage through git: https://git.xpub.nl/XPUB/SI18
Ghostology
https://www.youtube.com/playlist?list=OL+K5uy_kofB1UsJ_37_0e0WcY2kJKf68XIWBNSn8
Documentology
try to make a mini template for things we need
This is a guide, feel free to reply to the structure as you want.
title (eg.: Emma in a garden)
duration
description [one sentence summarise] (eg.: we want to record two parallel diaries of environmental sounds]
score [prompt, general overview] (eg.: we record diary entries)
input [raw material] (eg.: audio recordings)
tools [used but not seen/heard everything /from tools to softwares/ used to obtain the material and modify the material] (eg.: microphone, audacity)
process log [steps, process, curation] (eg.: 1. record audio 2. upload files on audacity 3. normalise effect on audacity; 4. export)
output [public outcome] (eg.: link to recording)
who? [the person/group that worked on it] (eg.: Emma and alex)
Documentation Logs
Week 01
Supi & Jian
[title]
Breadboard Experiments
[duration]
3:05
[description]
Using basic components to build a simple breadboard curcuit that works like a raw patchable synth for two musicians.
[score]
jam session, 1 person patching the cable, 1 person regulating the potentiometers
[input]
DIY patchable synth instrument, microphone
[tools]
2 Breadboards, 9V battery, power supply module, buzzer, rotary potentiometer, slide potentiometer, 8 jumper cables
[process log]
- breadboard baiscs: bulding simple LED setups from scratch
- adding potentiometers and buzzer to the curcuit
- building a setup that allows interaction of two people and a range in the sound of the buzzer
- documenting the whole process
- recording a jam session
- upload file
[output]
audio file, video file
[who]
Supi & Jian
al and emm
title: "parallel recording diaries"
duration: 01.00-01.20 minutes x 7 files: around 08:00 minutes.
description: We made two parallel recordings throughout the day: one of us at home the other travelling, to create a contrasting experience. The purpose was to create, through parallel field recordings, a feeling of displacement to the listener, that is positioned in one place and listening to what is happening in two other places at the same time.
score: We recorded, at the same moment of the day, the sounds around us, opening the recording with a documental description of when, where, and what was happening. Afterwards, the recordings have been mixed together: one comes from the right and one from the right, so that they could be listened to separately (two monos) or also merged (stereo), depending on the media used.
input [raw material]: field recordings
tools [used but not seen/heard everything /from tools to software/ used to obtain the material and modify the material]: two brains, a mini-microphone, a phone, Audacity.
process log [steps, process, curation]: 1. record the audio 2. upload the files on audacity 2. normalise, loudness normalisation, noise reduction effects on audacity 3. set alex on the right and emm on the left. 4. export .wav file
output [public outcome]: alexemm.mp3
who? [the person/group that worked on it]: Alex and Emm
mitsa and erica
title: "no birds on field recordings"
duration: 5:16
description: An audio track with parts of mitsa's and erica's conversations, one evening at nordplein. It is composed as two parallel monologues. On the left speaker is mostly erica's voice and on the right side mostly mitsa's. Talkin mostly about public space, field recording in public spaces, the position of the one that records and the one that is being recorded, the difference between soundscape and pure library sounds, how to choose what is urgent to be published, while the sounscape of nord plein is present
score: start recording in a public space while we have a free conversation.
input [raw material]: field recordings
tools [used but not seen/heard everything /from tools to software/ used to obtain the material and modify the material]: zoom recorder, reaper for editing.
process log [steps, process, curation]: 1. meet at nord plein 2. record the soundscape while discussing 3. choice of the material and edit
output [public outcome]: [1]
who? [the person/group that worked on it]: mitsa and erica
Week 02
Miri & Emma
title: "Your personal guide to making sound"
duration: 03.08
description: We produced an instructional piece that does not follow the basic rules of the type of text: the instructions are broken down, disordered and messy, not linear, neither clear nor straight.
score: We wrote a text based on the [Prototypology] page, which contains lists of instructions, descriptions and information. We brought it to absurdity and produced a recording using a computer voice.
input: a piece of instructional text
tools: two brains, a mini-microphone, Audacity, eSpeak.
process log: 1. written the text 2. tried out multiple computer voices on different software 2. upload files on audacity 3. normalise effect on audacity; 4. tried out different effects in audacity 5. deleted useless silences 6. cut out errors 7. export .wav file
output: yourpersonalguidetomakingsound.mp3
who?: Miri and Emm
Jian & Kimberley
[Title]
Uneven pattern
[Duration]
6'23
[Description]
Apply the principles of weaving techniques to create a visual pattern (notation sheet) and translate into an audio piece. The audio piece is intended to bind several contributions together and can be “cut” to insert other sound pieces.
[Score, prompt, general overview]
Designing a notation system using a simple grid to translate a visual pattern into a sound pattern.
[Input]
Various audio recordings
[Tools]
Miscellaneous objects to create sound, microphone to record, Audacity to edit and arrange sound
[Process log]
SOUND SAMPLES
1. Defining a number of elements to use in the pattern (in this case: 4)
2. Record as many sound samples as the number of elements defined in the previous step using a variety of mundane objects.
3. Define a unique length for all elements.
NOTATION SHEET
1. Define the length of the sound piece.
2. Horizontal axis: Divide the length of the sound piece by the length of the sound samples previously defined.
3. Vertical axis: Define an amount of track (or ‘layers’)
4. Trace a grid respecting the numbers previously defined.
5. Define a colour for each sound sample.
6. Colour cells to create a pattern.
note: Silent cells are marked with a ‘/’.
INTERPRETATION
1. With a sound editing software, convert the notation sheet in a sound piece by manually arranging the sound samples in their respective positions (defined by the coloured pattern).
note: Silence cells will be translated to silent break which length equals to the sound sample’s length.
2. Export as mp3.
note: Externally designed sound pieces can be inserted in the pattern. To do so, create the insert in the notation sheet first, and make the insert in the sound file by placing the new sound according to its position in the notation sheet.
[Output]
[Who]
Jian and Kimberley
Grgr & Chae
[title]
"Critical Evaluation of Crunchy and Crispy Texture" from Issue number 1 of "The Perfect Crunch International Journal", Patterns of Crunchiness to Satisfy Your Bored Mouth
[duration]
05:24
[description]
Based on Erica's diagram of crunchiness and other textures of foods, Chae and Grgr decided to initiate crunch research group. As our first activity, we reviewed the academic paper in ASMR format. With an intention to bring the extreme pleasure of academic papers, crunchy essays to pleasure your brain and hunger for knowledge.
[score_prompt, general overview]
Title | Abstract | Table of crunchiness (Sensory) | Mechanical Aspects | Acoustical Aspects | Conclusion | Outro
[input]
audio recordings (1. recordings at recording room with dynamic mic 2. recordings with iPhone with iRig mic)
[tools]
- Audacity
- Foods (almond, apple, bugles natural, cacao nibs, celery, coconut, cucumber, fried onions, lettuce, paprika, fried uncooked ramen, veggie chips, walnut)
- dynamic mics, iRig mic, iPhone
- academic paper (CRITICAL EVALUATION OF CRISPY AND CRUNCHY TEXTURES: A REVIEW by Michael H. Tunick et al.) /
- jitsi
[process log]
- script: https://hub.xpub.nl/soupboat/pad/p/the_perfect_crunchiness
1) first meeting -> further develop the diagram
2) recording crunchy sounds
3) based on selected text, writing a script
4) second round of recording crunchy sounds and reading text
5) first rough editing - audacity
6) third round of recording
7) final editing - audacity (difficulties in creating automation on effects)
8) upload around 12:35 (2hs passed from the due date)










[output]
https://hub.xpub.nl/soupboat/SI18/02/recordings/patterns_of_crunchiness.mp3
The website (TBC on the soupboat)
[who?]
Crunch Research Group (grgr and Chae)
Mitsa & Supi & Kamo


title
Schooling Shoaling
duration
9:52
description
An exploration of pattern entrances and exits
score
Listen and adapt to the other players' rhythm
input
Audio file
tools
- Water bottles: 2 made of metal, 1 made of plastic
- Wooden branches
- Microphone
- Audacity
process log
1. Outside, at Spoorsingel. It's sunny and feels like summer
2. Read notes on the pad about uneven patterns
3. Discuss (keywords: inside-outside, entering-leaving patterns, constantly moving pattern(s), schooling and shoaling)
4. Drink water
5. Realize that everyone is drinking water
6. Realize that the water bottle is a common instrument
7. Gather branches
8. Hit record
9. Hit branches against water bottles
10. Sync energies and synergies
11. Swim with or against schools and shoals (and schoals)
12. Enter or leave as desired
output
schoolshoal.mp3
Carmen & Gersande & Alex
[title] are we on the same page?
[duration] 3:18
[description] Alex, Carmen and Gersande are sitting on a bench in a real fictional space. It is sunny around
them. A slight breeze brushing off their cheeks while they discuss something of utmost importance: what is happening around them.
[score] Following a blank script, we recorded observations of what was happening around us and our thoughts to create a real fictional space.
[input] voice audio recordings & recordings of some sounds



[tools]
recorded with personal cell phones and zoom h5
mixed and edited on Audacity
[process log]
- tba
- tba
- ...
[output]
▶ recording
▶ notation
[who?] Gersande, Carmen & Alex
Week 03
Emergent Opera
PAD: https://pad.xpub.nl/p/SI18_three
Care Takers : Erica, Gersande and Kamo
Kamo & Supi
title: Overture Atlas
duration:
description: A landscape that hosts other contributions and an instrument that composes the Emergent Opera
score: see Figma
input: text
tools: Telegram, Etherpad, Figma
process log:
1. Come up with prompts for the Overture Atlas
2. Mock up potential starting points
3. Design the atlas
output: https://issue.xpub.nl/18/archive/03/
who: Kamo, Supi
Gersande
[title]
Entr'actes
[duration]
Entr'acte 1 (02:01)
Entr'acte 2 (00:29)
Entr'acte 2_2 (01:50)
Entr'acte 3 (04:06)
[description]
The Entr'actes 1., 2. and 3. are the intermissions of the Emergent Opera. Meant as a one-person orchestral interlude for a listener's ears, the Entr'actes are musical narration with no intelligible language.
Entr'acte 1. is an improvised piece where the player talks through the trumpet, rather than playing the trumpet, resulting in scratchy sounds and chaotic rhythms and intentions.
Entr'acte 2. is a naïve score, transcribed from an improvised numerical chant.
Entr'acte 3. uses the noise signifier of a poem rather than the signified sounds of that poem and the story it could tell.
This research is an attempt at squeezing inner emotions out of words, not to distract the listener from feeling, while looking for meaning.
[score]






[input]
Voice and Trumpet
[process log]
Glossary examination
Improvisation
Transcript improvisation into scores
Played scores
[tools]
Zoom H5
Audacity
[output]
audio file
ENTR'ACTE 1 - LISTEN
ENTR'ACTE 2 - LISTEN
ENTR'ACTE 2.2 - LISTEN
ENTR'ACTE 3 - LISTEN
Emm & Jian
[title]
Act I – Within an entangled state.
[duration]
6:24
[description]
Enter two voices in the middle of a conversation. Their words are floating through 10 contingent streams of thoughts, interweaving, inter-acting, intra-acting, reflecting, distorting, diffracting …
[score]
A conversation via voice messages is used to create an unconventional duet.
[input]
voice messages
[tools]
mobile phone, Telegram, Audacity, Descript
[process log]
- brainstorm
- experiment separately with different voices to check effect options on audacity
- choose a text to work with
- decide on a methodology = how to read/interpret the text
- record conversation and convert audios from OGG to WAV
- upload audios on audacity --> what effects make sense with the text we've created?
- experimenting on audacity
- compose the music (editing audio files with effects and cuttings to produce baseline, choruses and sound effects)
- add audios to Descript to create a transcription for the different streams to include in the libretto
- organize transcriptions in a text file and add stage directions
- finishing touches
- preparing the files to adapt to the final release: edit>clip bounderies>join + effect>truncate silence
- upload files
[output]
audio file and libretto
[who]
Emm & Jian
Miri & Carmen
Inspired by the song Slush, by Bonzo Dog Club, from their album Let's Make Up and be Friendly, released in 1972 by EMI records Ltd, we decided to do a laughing opera piece. Playing with different sounds of laughter coming together, from Miri's audio samples collected from Youtube to the ones added by Carmen, resulting in music.
Transcription of the piece:
Hmm.
Yeah.
Same. This isn't funny. No of course not.
Tools: Audacity, Ableton, Descript, ToneTransfer, SampleSwap, FreeSound, Sample Focus, Youtube, MP3 Converter
Curtain Call/Grand Finale/Finale
[title]
tbc
[duration]
The duration of this piece varies depending on the length of the sound piece it comes to "parasite". End-to-end, the piece has 53 seconds of sound.
[description]
12 sound interferences and a set of instructions on how to apply them to an existing sound piece.
[score]
A series of intentional and non intentional, human and non human sounds intended to discreetly interfere with the entire piece upon a given set of instructions.
[input]
human voice, iphone vibration, downloaded wav. files of various human and non human sounds
[tools]
mic
audacity
[process log]
There were some constraints:
First, I (Chae) am not familiar with 'Opera'. Never watched the opera before. only seen a second-hand depiction of it in movies, novels or heard from other people's experiences.
Second, I did not want to make a dialogue piece this week.
While walking with Kimberley, we talked about the awkwardness when watching a very quiet art performance, or classical music concert, etc. We intend to focus on traditional set-up of the opera: the heavy atmosphere, clear division between the stage and the audience.
Have you ever hold your breath or cough during the performance? Or have you ever struggled not knowing when to clap so you just wait until someone claps? Or even worse, were you the one who clapped in wrong moment?
What if the grand finale is stretched out through the whole opera piece? It builds up but with the sound that would be considered as interruption. We wanted to explore Keywords: applause, awkwardness, interruption,
Notes while making the sound: It was very difficult to set up the right setting. I wish there is a explanation drawing not only which input goes to which, but also what these numbers mean and what is the most basic setting for recording a voice. With this numbers and overview sketch, I can always get back to this number/sketch as a guidance and start from there. Since everyone use different inputs and different settings, and then do not change them back to what they were before, I can not guarantee the stable sound quality. Especially when you are in a hurry and just quickly want to record the sound and then go, this is problematic.
In the end I cannot use the recorded sound because the input sound of the mic was too small and the noise from the machine is too loud. At the moment I am frustrated a bit because I couldn't pic this up during the recording session.
[output]
Instruction for Grande Finale
The Grande Finale is a contribution that is discreetly interfering with the rest of the piece. It displays a selection of intentional and non intentional, human and non human sounds often filling the audience-side of a concert hall, a cinema room, a theatre, etc. The amount of disturbances is gradually increasing until melting into the Finale as a cheerful manifestation of appreciation.
1. For the total length of the final piece (all contributions except this one) define 9 equal slots. The first slot will start at 0'00. Name the slots as such: "slot #1, slot #2" and so on until "slot #9".
eg: if the total length of the piece is 18 minutes long, mark a slot at 0’00, 2’00, 4’00, 6’00’, 8’00, 10’00, 12’00, 14’00 and 16’00
2. After the end of the piece (end of slot #9), add a slot of the same length, this will be "slot #10".
eg: If the total length of the piece is 18 minutes and each slot has a length of 2 minutes, add a 2 minutes slot after minute 18'00.
In the following steps, we ask you to place specific sounds at specific slots. These sounds are meant to overlap with the other contributions but chance might be that some of them won't be fully audible, this is alright.
Each sound file is named by a letter and ordered alphabetically. Each sound or sequence of sounds should start at the beginning of each slot. Some sounds will overlap, some sounds will be played in sequence. In the case of a sequence, the interval time will be mentioned. If no interval time is mentioned, the interval time is inexistent.
Slot #1: "a"
Slot #2: "b"
Slot #3: "c" and "d" in overlap
Slot #4: "e"— 1 second interval—"f"
Slot #5: "g"—2 seconds interval—"h"
Slot #6: "i"—1 second after "i" starts overlap sound "j"
Slot #7: "k"
Slot #8: "l"—"m"—"n"
Slot #9: "o"—3 seconds interval—"p" and "q" in overlap—2 seconds interval—"r"—"s" and "t" in overlap.
Slot #10: "u", "e", "p", "q" and "k" in overlap.
[who]
Kimberley and Chae
Week 04
The jingle board Parliament
pad here: https://pad.xpub.nl/p/SI18_four
Caretakers: Grgr, Miri, Mitsa
Gersande & Jian
[title]
[duration]
00:42 Alexandra Ocasio Cortez
00:04 Cheering-Applause.mp3
00:24 Bob Ross
00:02 Thank-You.mp3
00:04 Kamala Harris
00:01 Well-Said.mp3
00:39 Miriam Margolyes
00:05 Ha-ha.mp3
00:11 Owen Unruh
00:02 Do-That.mp3
00:02 Robert Habeck
00:01 Just-Bam.mp3
00:09 Rumors say it is James Baldwin
00:01 Just-Same.mp3
00:17 Tony and Ezekiel
00:01 Who-s-Tony.mp3
00:01 Fuck-You.mp3
[description]
pop-cultural and political audios that went viral
[score]
[input]
[tools]
Youtube, Instagram, Tictoc, Audacity
[process log]
[output]
audio file, video file
[who]
Gersande & Jian
Gersande
[title]
Objects of the Parliamant
[duration]
00:02 Astonish_Glass
00:03 Blue_Pen
00:02 Bottle_Water
00:04 Chair_Man
00:02 Creacky_Floor
00:04 Sad_Suit
00:04 Showcase_Briefcase
00:06 Sneaky_snickers
00:03 Tameless_Table
00:03 Tight_Tie
[description]
Personified mundane objects
[score]
[input]
Voice
[tools]
Audacity
[process log]
[output]
audio file
[who]
Harold and Gersande
Al & Mitsa



[title] Getting Political: Re-making Anthems & Money Talks
[duration] 6 short snippets with length between 0:14 and 0:38 min
[description] Re-enacting quotes from 3 bulgarian politicians and re-mixing the Sound of Happiness, Te Deum and the greek, the bulgarian and the duth national anthem
[score]
[input] Alex recorded the quotes with OS' Spoken Content option. Mitsa recorded guitar, voice and synth and processed one percussive sample
[tools] OS' Spoken Content, Audacity, Reaper, electric guitar, keybord synth
[process log] our process pad is here. We started by drafting ideas and what was most interesting for us at the moment, was focusing on some political contexts. Mitsa was experimenting with remixing national anthems already and Alex was having fun with exploring some iconic quotes of the Bulgarian statesmen over the past 35 years of Bulgaria's transition to democracy and market economy. Our common topic is "Getting Political" and then each of us focused on creating 3 snippets on our sub-topics - anthems & quotes. During the process, we were sharing the work on each step with each other and getting feedback.
▶Alex's process the first quote I selected was Zhivkov's one about money. Then, I was mainly looking for other quotes that are tackling the topic of money. When the politicians were saying those things, they were speaking in a vernacular manner, not using any high and official language.
Zhivkov and Borisov's quotes are also recorded on video. Saxe-Coburg-Gotha's quote is from a newspaper. I translated their quotes in English and then recorded them with my Mac's Spoken Content option using the voice of Daniel. Then, added some applause at the end. We were conserned about copyrights, that is why the pieces are re-created by us and not taken from the internet.
▶ Mitsa's process I was thinking of the current importance of nationalism for states and then had the idea of underlining that by messing around andremaking several anthems with a more pop sound. I remade the Eurovision anthem, the melody of Happiness and an anthem combining lyrics from the Greek, the Bulgarian and the Dutch. There are several ideas related to that gesture. First, by taking out the symphonic and classical sound of the anthems, they lose some of their glamor connected to the high and important musical past.Then by experimenting with contemporary conical elements, I underline how nationalism is present in today's systems and how power can be echoed through music. (tan tan tan, pretty big things). It was also really playful for me to mess around.
[output] Mitsa's Getting Political: Contemporary Anthems Anthem of Tolerrant Europe, First Robot Congressman, and National Anthem & Alex's Getting Political: Money Talks
▶ Todor Zhivkov: original quote vs. the recording
▶ "The Tsar" Simeon Borisov von Saxe-Coburg-Gotha: the recording
▶ Boyko Borisov: original quote vs. the recording
[who?] Alex & Mitsa
Kimberley & Supi
title: "dear Dear"
duration:
description: A set of short excerpts from movie characters reading aloud letters they wrote or received.
score: Letters in movies
input: audio files from movies
tools: Youtube, youtube > mp3, Audacity
process log: (pad)
1. Even though we could recall many scenes of movie characters reading letters aloud, most of our task was spent trying to find video snippets of these exact scenes online (in a limited amount of time).
2. If we were lucky that the said scenes were so crucial that someone had shared them on Youtube, we downloaded their sound files and trimmed them in Audacity to only keep their short beginnings.
3. We questioned whether the content of the "letters" was essential or not, but came to the conclusion that our focus should stay on the few first words (and other nonverbal cues such as voice tone, music (underscore), silence breaks) that set the specific atmosphere in movies when letters are being read.
output: 10 excerpts from 10 movie characters reading letters aloud.
–Don Johnston (Broken Flowers, Jim Jarmush)
–Dr Donald (Green Book, Peter Farrelly)
–Julia (Julie & Julia, Nora Ephron)
–Madeleine (Vertigo, Alfred Hitchcok)
–Marty (Back to the future, Robert Zemeckis)
–Paddington (Paddington, Paul King)
–Saajan (The Lunchbox, Ritesh Batra)
–Savannah (Dear John, Lasse Hallström)
–Suzie (Moonrise Kingdom, Wes Anderson)
–Theodore (Her, Spike Jonze)
sources:
Categorie:Implicancies
Blow Up, "La lettre au cinema" (Arte) english: "Letters in cinema"
"Voice over letter", Tv tropes
"Most Popular Movies and TV Shows tagged with keyword "letter"", IMDB
who: Supi and Kimberley
Kamo and Miri
Title: -
Duration: -
Input: Own recordings and audio files from Youtube
Output: Own recordings and snippets from Youtube audio files
Tools: Youtube, Audacity, Ableton, MP3 Converter
Week 05
Supi & Alex
[title] What Is Left To Discuss?
[duration] 3:05 min
[description] A conversation piece about art: what is it for us, as makers, how do we censor ourselves and why.
[input] audio recording of our voices; audio recording of noise made with Kastle
[tools] Kastle, Macbook pro, Audacity
[process log]
- We started with some collective writing. The idea was to create a conversation by asking each other questions and answering them. We had an empty script with each of us writing something one after another.
- The text was created over 3 days. We both asked each other questions and answered them.
- Then, we recorded our conversation using an online call.
- In order to add an underscore, we produced various noises on Kastle at Supi's restaurant. Used one of them, looped it and added it to the mix.
- We had the idea to censor parts of our conversation. However, while listening to it, we decided to keep it as it is. It became a quite honest and open conversation and we shared things we wouldn't normally say in a conversation outside this setting.
[who] Supi & Alex
Erica & Jian
[title]
[duration] 08:37 min
[description] A collective poem about art and censorship
[input] live audio recording of a collective reading
[tools] Phone, Audacity
[process log]
- As a way to collectively write a text we came up with this method: The starting sentence would be a parent-folder on the soupboat and each of us would add subfolders, sub-sub-folders and so on to continue the sentence while creating new branches.
- The folder structure was built using the terminal only.
- We then built a python-function that reads through the whole folder structure, starting from the parent-folder and following the different branches to all last children. All paths are written to a text file, using indentation to visualize the hierarchy of the folder structure.
- The result is a text file that reads through 55 paths in a poem-like structure.
- The collective reading of the poem followed no rules except intuition and was recorded.
[who] Erica & Jian
Emm & Kamo
[title]
what is right not to
[duration]
3.36
[description]
In connection with the topic of censorship, the research and the questions on the value of something that it's worth it to stay as it is, because of what and how it is already.
[score]
what is the notation system of the instrument?
There is a structure in the text used:
[underlined are the repetitive words]
if we censor art, what is left to discuss? but what is right not to nor to or to to + verb* [*variable]
The basic structure that should be kept in the played piece have to contain:
1. First line [the refrain]: if we censor art, what is left to discuss?
2. Container of the text: 2 "but" [one after the first line & one as the final line]
3. The text:
repetitive word:
what is right not to
not to
nor to
or to
to + the variable verb
[input]
collectively written text and audio recordings
[tools]
mini-microphone, Ableton, Audacity, Rack
[process log]
- brainstorm
- pick a topic we want to write about
- pick a method we want to use
- start writing together on the same pad
- edit the text & proofread
- experiment audio recordings
- experiment with rack and our voices
- find the right method
- create a drum machine
1. record fragments
2. split them up in different audios
3. position audio recordings as notes
4. play!
- our usage of the notation system and the creation of the piece
1. pick verbs already divided in categories from the original text + the repetitive words
2. play around and create a rhythm out of them [see the fragments]
3. between the verbs, insert variations of what is right not to
4. add first line and containers [but]
5. done!
- export mp3
[output]
instrument/drummachine
audio piece
[who]
Emm & Kamo
Chae & Gersande
Miri & Mitsa
[title] MiMi
[duration] 4:34
[description] Two texts performed as spoken word with the same guitar loop as a basis and a different editing approach
[input] audio recording of our voices; looped guitar ; beat edot
[tools] mobile phone recorder, mini microphone, Ableton, Reaper, ambient effects, pitch effect
[process log]
- Both of us wrote a text that later we would perform [2]
- We made a guitar loop with some effects, which became a basis for the music part
- Mitsa recorded their part and used the pitch effect for detuning both the voice and the guitar
- Miri....
- We merged the two tracks to 1
[who] Miriam + Mitsa
Week 06
Mitsa & Alex

{kind=link}
{kind=link}
{kind=link}
[title] Diffracted Narrations
[description] This simple recipe for diffractive perception of information provided by two sources can be used on various types of pieces. However, one of the inputs should be a video and the other one - a written text. We create a new piece by muting the original narration of the video and adding a completely different one. This method allows us to experiment on conceptual level: what types of stories or thoughts we would like to play with? By experiencing one source through the other, creative and unexpected readings can emerge.
[input] Video and written text. In our experiment we used Denise Fereira Da Silva, Arjuna Neuman (2019), Four waters: deep implicancy as a video source and two poems by Parwana Amiri: Your Eyes Bother Us and How Hard
[tools] computer, mobile phone
[process log]
▶ process pad
- Pick two pieces:
-one video (ideally without subtitles and texts on it)
-a written text (article, poem, short story etc.)
- Video: if the video has audio, mute it
- Text:
-choose part of the written text that you would like to add as a new voice over of the video
- Perform the new piece by playing the video and narrating it live yourself
- Record the performance with video & audio
As a result, you will have a new piece with a diffracted narration.
[output] Our diffracted narration - one of the takes (not the final choice of poems).
[reads] Denise Fereira Da Silva, Arjuna Neuman (2019), Four waters: deep implicancy
Parwana Amiri (2019-2020), Your Eyes Bother Us and How Hard
Pages in category "Prototypology"
This category contains only the following page.